Find og fjern duplikerede rækker fra en SQL Server-tabel
Af: Sergey Gigoyan | Opdateret: 2019-08-16 | Kommentarer (11) | Relateret: Mere > Databasedesign
Problem
I henhold til de bedste fremgangsmåder i databasedesign bør en SQL Server-tabel ikke indeholde dubletter. Under databasedesignprocessen skal der oprettes primærnøgler for at eliminere duplikerede rækker. Imidlertid er vi undertiden nødt til at arbejde med databaser, hvor disse regler ikke følges, eller undtagelser er mulige (når disse regler omgåes bevidst). For eksempel, når en iscenesættelsestabel bruges, og data indlæses fra forskellige kilder, hvor der er mulige duplikatrækker. Når indlæsningsprocessen er afsluttet, skal tabellen renses, eller rene data skal indlæses i en permanent tabel, så derefter er der ikke længere brug for duplikater. Derfor opstår et problem vedrørende fjernelse af dubletter fra indlæsningstabellen. I dette tip skal vi undersøge nogle måder til at løse behovet for data-duplikering.
Løsning
Vi vil overveje to tilfælde i dette tip:
- Det første tilfælde er, når en SQL Server-tabel har en primær nøgle (eller et unikt indeks), og en af kolonnerne indeholder duplikatværdier, som skal fjernes.
- Det andet tilfælde er, at tabellen ikke har en primær nøgle eller eventuelle unikke indekser og indeholder duplikatrækker, som skal fjernes. Lad os diskutere disse tilfælde separat.
Sådan fjernes duplikatrækker i en SQL Server-tabel
Kopier af poster i en SQL Server-tabel kan være et meget alvorligt problem. Med duplikatdata er det muligt for ordrer at blive behandlet adskillige gange, har unøjagtige resultater til rapportering og mere. I SQL Server er der en række måder at adresse duplikatposter på i en tabel baseret på de specifikke omstændigheder såsom:
- Tabel med unikt indeks – For tabeller med et unikt indeks har du muligheden for at bruge indekset for at ordre identificere de duplikerede data, og fjern derefter duplikatrekordene. Identifikation kan udføres med selvtilslutninger, ordning af data efter den maksimale værdi, ved hjælp af RANK-funktionen eller ved hjælp af NOT IN-logik.
- Tabel uden et unikt indeks – For tabeller uden et unikt indeks er det lidt mere udfordrende. I dette scenarie kan ROW_NUMBER () -funktionen bruges med et fælles tabeludtryk (CTE) til at sortere dataene og derefter slette de efterfølgende duplikatposter.
Se eksemplerne nedenfor for at få eksempler fra den virkelige verden om, hvordan du sletter duplikaterekorder fra en tabel.
Fjernelse af duplikaterækker fra en SQL Server-tabel med et unikt indeks
Opsætning af testmiljø
For at udføre vores opgaver, vi har brug for et testmiljø:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Lad os nu indsætte data i “TableA”:
Som vi kan se, findes værdierne 3 og 5 i kolonnen “Værdi” mere end én gang:
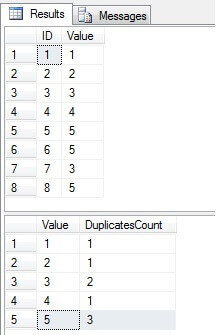
Identificer duplikerede rækker i en SQL Server-tabel
Vores opgave er at håndhæve unikheden for kolonnen “Værdi” ved at fjerne dubletter. Fjernelse af duplikatværdier fra tabel med et unikt indeks er lidt lettere end at fjerne rækkerne fra en tabel uden den. af alt skal vi finde dubletter. Der er mange forskellige måder at gøre det på. Lad os undersøge og sammenligne nogle almindelige måder. I koden nedenfor er der seks løsninger til at finde ud af, at duplikatværdier, der skal slettes (efterlader kun en værdi):
Som vi kan se, er resultatet for alle tilfælde det samme:
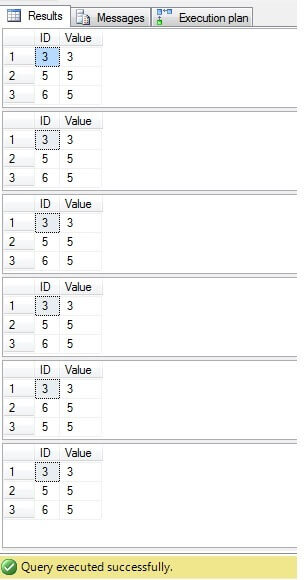
Kun rækker med ID = 3, 5, 6 skal slettes. Når vi ser på udførelsesplanen, kan vi se, at den nyeste – den mest “kompakte” løsning (“Løsning 6”) har de højeste omkostninger (i vores eksempel er der en primær nøgle i kolonnen “ID”, så “NULL” -værdier er ikke mulige for den kolonne fungerer derfor “NOT IN” uden problemer), og den anden har de laveste omkostninger:

Sletning Dupliserede rækker i en SQL Server-tabel
Nu ved at bruge disse forespørgsler, lad os slette duplikatværdier fra tabellen. Forenklet vores proces, vi bruger kun det andet, det femte og det sjette forespørgsel:
Når vi sletter dataene og ser på udførelsesplanerne igen, ser vi, at den hurtigste er den første SLET-kommando, og den langsomste er den sidste som forventet:
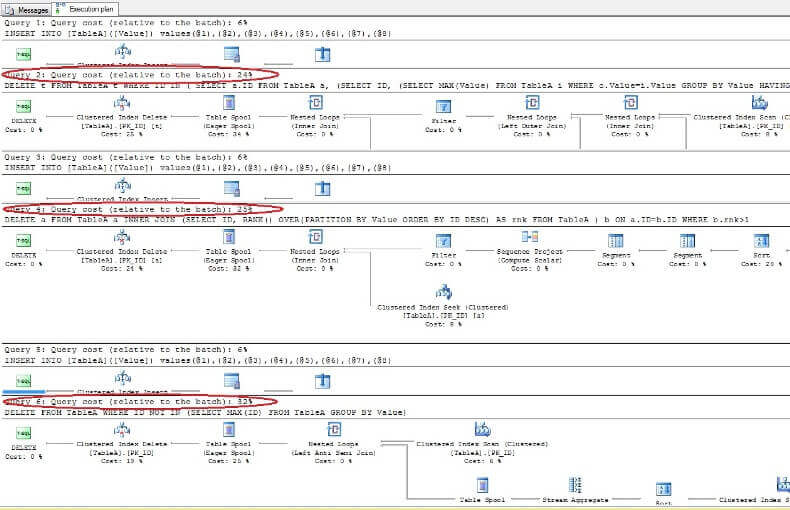
Fjernelse af dubletter fra tabellen uden et unikt indeks i ORACLE
Som et middel til at illustrere vores sidste eksempel i dette tip vil jeg forklare nogle lignende funktioner i Oracle. rækker fra t stand uden et unikt indeks er lidt lettere i Oracle end i SQL Server. Der er en ROWID-pseudokolonne i Oracle, som returnerer adressen på rækken. Det identificerer unikt rækken i tabellen (normalt også i databasen, men i dette tilfælde er der en undtagelse – hvis forskellige tabeller gemmer data i samme klynge, kan de have den samme ROWID).Forespørgslen nedenfor opretter og indsætter data i tabellen i Oracle-databasen:
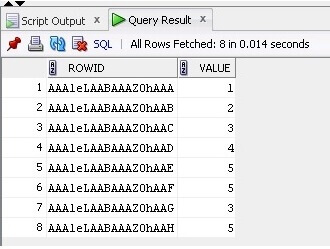
Nu vælger vi dataene og ROWID fra tabellen:
SELECT ROWID, Value FROM TableB;
Resultatet er nedenfor:
Nu bruger vi ROWID, fjerner vi let duplikatrækker fra tabel:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Vi kan også fjerne dubletter ved hjælp af nedenstående kode:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Fjernelse af duplikater fra en SQL Server-tabel uden et unikt indeks
I modsætning til Oracle er der ingen ROWID i SQL Server, så fjern duplikater fra tabellen uden et unikt indeks, vi skal udføre yderligere arbejde for at generere entydige identifikatorer:
I koden ovenfor opretter vi en tabel med duplikatrækker. Vi genererer unikke identifikatorer ved hjælp af ROW_NUMBER () -funktionen og ved at bruge fælles tabeludtryk (CTE) sletter vi dubletter:
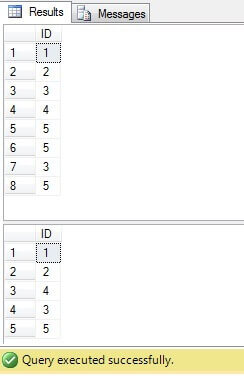
Denne kode kan dog erstattes med en mere kompakt og optimal kode:
Når det er sagt, er det også muligt at identificere den fysiske adresse på række SQL-serveren. På trods af at det praktisk talt er umuligt at findeofficiel dokumentation om denne funktion, kan den bruges som en analog til ROWIDpseudo-søjlen i Oracle. Det kaldes %% physloc %% (siden SQL Server 2008) og det er en virtuel binær (8) kolonne, der viser rækkenes fysiske placering. Da værdien af %% physloc %% er unik for hver række, kan vi bruge den som en rækkeidentifikator, der fjerner duplikerede rækker fra en tabel uden et unikt indeks. Således kan vi fjerne duplikatrækker fra en tabel uden et unikt indeks i SQL Server som i Oracleas, som i tilfældet, når tabellen har et unikt indeks.
De første to forespørgsler nedenfor er de ækvivalente versioner af fjernelse af duplikater i Oracle, de næste to er forespørgsler til fjernelse af duplikater ved hjælp af %% physloc %% similarto tilfældet med tabellen med et unikt indeks, og i sidste forespørgsel, %% physloc %% bruges ikke kun til at sammenligne ydeevnen for alle disse muligheder:
Når vi analyserer udførelsesplanerne, kan vi se, at de første og de sidste forespørgsler er de hurtigste sammenlignet med den samlede batch gange:
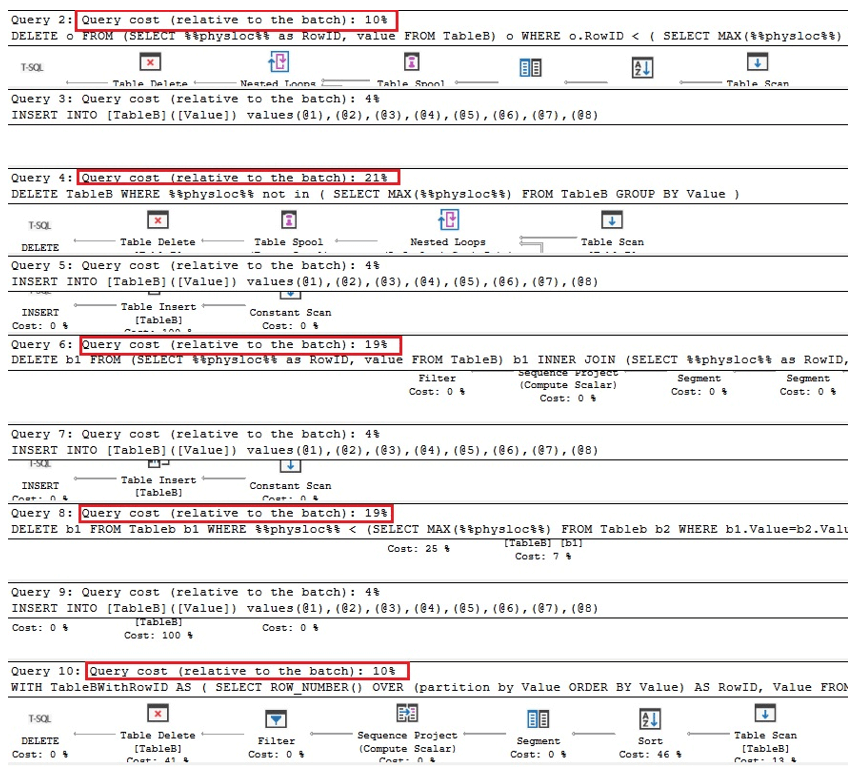
Derfor kan vi konkludere, at brug af %% physloc %% generelt ikke forbedrer ydeevnen. Mens du bruger denne fremgangsmåde, er det meget vigtigt at indse, at dette er en udokumenteret funktion i SQL Server, og derfor skal udviklere være meget forsigtige.
Der er andre måder at fjerne dubletter på, som ikke diskuteres i dette tip. For eksempel kan vi gemme forskellige rækker i en midlertidig tabel og derefter slette alle data fra vores tabel og derefter indsætte forskellige rækker fra den midlertidige tabel til vores permanente tabel. I dette tilfælde skal DELETE og INSERT-udsagn indgå i en transaktion.
Konklusion
Under vores erfaring står vi over for situationer, hvor vi har brug for at rense duplikatværdier fra SQL Server-tabeller. Duplikatværdierne kan være i kolonnen, som vil være over-duplikeret baseret på vores krav, ellers kan tabellen indeholde duplikatrækker. I begge tilfælde er vi nødt til at ekskludere dataene for at undgå duplikering af data i databasen. I dette tip forklarede vi nogle teknikker, som forhåbentlig vil være nyttige til at løse disse typer problemer.
Næste trin
Senest opdateret: 2019-08-16


Om forfatteren
 Sergey Gigoyan er en databaseprofessionel med mere end 10 års erfaring med fokus på databasedesign, udvikling, performance tuning, optimering, høj tilgængelighed, BI og DW design.
Sergey Gigoyan er en databaseprofessionel med mere end 10 års erfaring med fokus på databasedesign, udvikling, performance tuning, optimering, høj tilgængelighed, BI og DW design. Se alle mine tip
- Flere databaseudvikler-tip …