Algoritmo de classificação rápida
A classificação rápida é uma das diferentes técnicas de classificação que se baseia no conceito de dividir e conquistar, assim como mesclar classificação. Mas na classificação rápida, todo o trabalho pesado (trabalho principal) é feito durante a divisão da matriz em submatrizes, enquanto no caso da classificação por mesclagem, todo o trabalho real acontece durante a mesclagem das submatrizes. No caso de classificação rápida, a etapa de combinação não faz absolutamente nada.
Também é chamada de classificação de troca de partição. Este algoritmo divide a lista em três partes principais:
- Elementos menores que o elemento Pivot
- Elemento Pivot (elemento central)
- Elementos maiores que o Elemento dinâmico
O elemento dinâmico pode ser qualquer elemento da matriz, pode ser o primeiro elemento, o último elemento ou qualquer elemento aleatório. Neste tutorial, tomaremos o elemento mais à direita ou o último elemento como pivô.
Por exemplo: Na matriz {52, 37, 63, 14, 17, 8, 6, 25}, pegamos 25 como pivô. Portanto, após a primeira passagem, a lista será alterada assim.
{6 8 17 14 25 63 37 52}
Portanto, após a primeira passagem, o pivô será definido em sua posição, com todos os elementos menores à sua esquerda e todos os elementos maiores do que à direita. Agora 6 8 17 14 e 63 37 52 são considerados como dois sunarrays separados, e a mesma lógica recursiva será aplicada a eles, e continuaremos fazendo isso até a matriz completa é classificada.
Como funciona a classificação rápida?
A seguir estão as etapas envolvidas no algoritmo de classificação rápida:
- Depois de selecionar um elemento como pivô, que é o último índice da matriz em nosso caso, dividimos a matriz pela primeira vez.
- Na classificação rápida, chamamos isso de particionamento. Não é simples quebrar a matriz em 2 submatrizes, mas no caso de particionamento, os elementos da matriz são posicionados de forma que todos os elementos menores que o pivô fiquem no lado esquerdo do pivô e todos os elementos maiores que o pivô estejam estar do lado direito dele.
- E o elemento pivô estará em sua posição de classificação final.
- Os elementos à esquerda e à direita podem não ser classificados.
- Em seguida, escolhemos subarrays, elementos à esquerda do pivô e elementos à direita do pivô e executamos o particionamento deles escolhendo um pivô nos submatrizes.
Vamos considerar uma matriz com valores {9, 7, 5, 11, 12, 2, 14, 3, 10, 6}
Abaixo, temos uma representação pictórica de como a classificação rápida classificará a matriz fornecida.
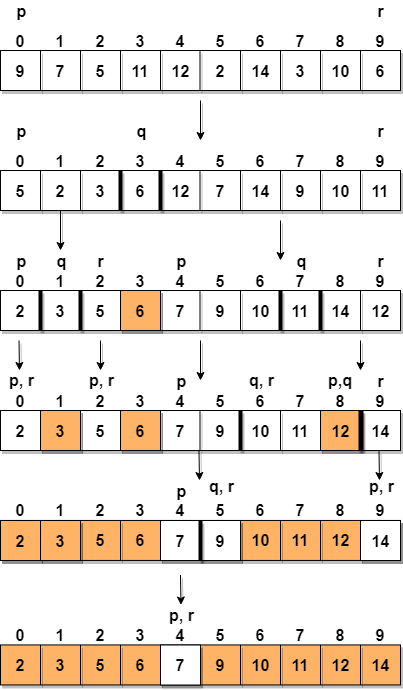
Na etapa 1, selecionamos o último elemento como o pivô, que é 6 neste caso, e chamar partitioning, portanto, reorganizar g o array de tal forma que 6 seja colocado em sua posição final e à sua esquerda estarão todos os elementos menores que ele e à sua direita teremos todos os elementos maior do que isso.
Em seguida, escolhemos o subarray à esquerda e o subarray à direita e selecionamos um pivô para eles, no diagrama acima, escolhemos 3 como pivô para o subarray esquerdo e 11 como pivô para o subarray direito.
E novamente pedimos partitioning.
Implementando o algoritmo de classificação rápida
Abaixo, temos um programa C simples que implementa o algoritmo de classificação rápida:

Análise de complexidade de classificação rápida
Para uma matriz, na qual o particionamento leva a submatrizes desequilibrados, a uma extensão em que no lado esquerdo não há elementos, com todos os elementos maior do que o pivô, portanto, no lado direito.
E se continuar recebendo submatrizes desequilibrados, a execução O tempo de execução é o pior caso, que é O(n2)
Onde, como se o particionamento levasse a submatrizes quase iguais, o tempo de execução é o melhor, com complexidade de tempo como O (n * log n).
Pior caso de complexidade de tempo: O (n2)
Melhor caso de complexidade de tempo: O (n * log n)
Complexidade de tempo médio: O (n * log n)
Complexidade do espaço: O (n * log n)
Como sabemos agora, que se o particionamento de subarrays é produzido após o particionamento são desequilibrados, a classificação rápida levará mais tempo para ser concluída. Se alguém souber que você escolhe o último índice como pivô o tempo todo, ele pode intencionalmente fornecer uma matriz que resultará no pior caso de tempo de execução para classificação rápida.
Para evitar isso, você pode escolher aleatoriamente elemento pivô também. Não fará nenhuma diferença no algoritmo, pois tudo o que você precisa fazer é escolher um elemento aleatório da matriz, trocá-lo por um elemento no último índice, torná-lo o pivô e continuar com a classificação rápida.
- O espaço necessário para a classificação rápida é muito menor, apenas
O(n*log n)espaço adicional é necessário. - A classificação rápida não é uma técnica de classificação estável, então ela pode alterar a ocorrência de dois elementos semelhantes na lista durante a classificação.
Agora que aprendemos a classificação rápida algoritmo, você pode verificar esses algoritmos de classificação e suas aplicações também:
- Classificação por inserção
- Classificação por seleção
- Classificação por bolha
- Classificação de mesclagem
- Classificação de heap
- Classificação de contagem