Finn og fjern dupliserte rader fra en SQL Server-tabell
Av: Sergey Gigoyan | Oppdatert: 2019-08-16 | Kommentarer (11) | Relatert: Mer > Database Design
Problem
I henhold til best practices for databasedesign, bør en SQL Server-tabell ikke inneholde dupliserte rader. Under databasedesignprosessen bør primærnøkler opprettes for å eliminere dupliserte rader. Noen ganger trenger vi imidlertid å jobbe med databaser der disse reglene ikke følges eller unntak er mulig (når disse reglene er forbigått bevisst). For eksempel når en iscenesettingstabell blir brukt og data blir lastet fra forskjellige kilder der dupliserte rader er mulige. Når lasteprosessen er fullført, bør tabellen rengjøres eller rene data skal lastes inn i en permanent tabell, så etter dette er ikke duplikater lenger nødvendig. Derfor oppstår et spørsmål om fjerning av duplikater fra lastetabellen. I dette tipset kan vi undersøke noen måter å løse behov for dataav duplisering på.
Løsning
Vi vil vurdere to tilfeller i dette tipset:
- Det første tilfellet er når en SQL Server-tabell har en primærnøkkel (eller unik indeks) og en av kolonnene inneholder dupliserte verdier som skal fjernes.
- Det andre tilfellet er at tabellen ikke har en primærnøkkel eller noen unike indekser og inneholder dupliserte rader som skal fjernes. La oss diskutere disse tilfellene hver for seg.
Slik fjerner du dupliserte rader i en SQL Server-tabell
Dupliser poster i en SQL Server-tabell kan være et veldig alvorlig problem. Med dupliserte data er det mulig at bestillinger behandles flere ganger, har unøyaktige resultater for rapportering og mer. I SQL Server er det en rekke måter å adressere dupliserte poster i en tabell basert på de spesifikke omstendighetene, for eksempel:
- Tabell med unik indeks – For tabeller med en unik indeks har du muligheten til å bruke indeksen for å bestille, identifiser duplikatdataene, og fjern deretter duplikatrekordene. Identifikasjon kan utføres med selvtilslutninger, ordning av data etter maks verdi, bruk av RANK-funksjonen eller ved bruk av NOT IN-logikk.
- Tabell uten en unik indeks – For tabeller uten en unik indeks er det litt mer utfordrende. I dette scenariet kan ROW_NUMBER () -funksjonen brukes med et vanlig tabelluttrykk (CTE) for å sortere dataene og deretter slette de påfølgende duplikatposter.
Sjekk eksemplene nedenfor for å få eksempler fra virkelige verden om hvordan du sletter duplikatkoder fra en tabell.
Fjerning av dupliserte rader fra en SQL Server-tabell med en unik indeks
Testmiljøoppsett
For å utføre oppgavene våre, vi trenger et testmiljø:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
La oss nå sette inn data i «TableA»:
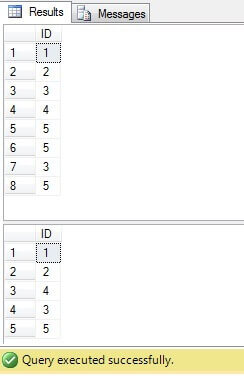
Som vi kan se, finnes verdiene 3 og 5 i kolonnen «Verdi» mer enn en gang:
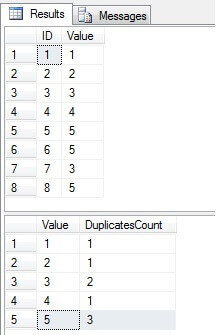
Identifiser dupliserte rader i en SQL Server-tabell
Vår oppgave er å håndheve det unike for «Verdi» -kolonnen ved å fjerne duplikater. Det er litt enklere å fjerne duplikatverdier fra tabellen med en unik indeks enn å fjerne radene fra en tabell uten den. av alt må vi finne duplikater. Det er mange forskjellige måter å gjøre det på. La oss undersøke og sammenligne noen vanlige måter. I koden nedenfor er det seks løsninger for å finne at dupliserte verdier som skal slettes (etterlater bare en verdi):
Som vi kan se, er resultatet for alle tilfeller det samme:
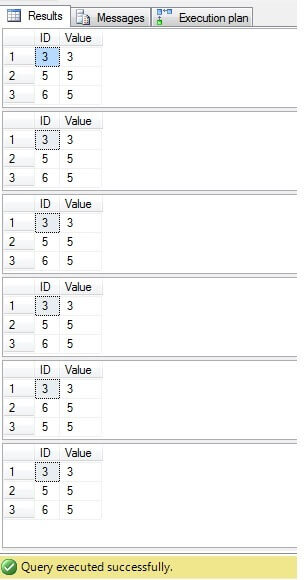
Bare rader med ID = 3, 5, 6 trenger å bli slettet. Når vi ser på utførelsesplanen, kan vi se at den nyeste – den mest «kompakte» løsningen («Løsning 6») har høyeste kostnad (i vårt eksempel er det en primærnøkkel i «ID» -kolonnen, så «NULL» -verdiene er ikke mulig for den kolonnen vil derfor «NOT IN» fungere uten problemer), og den andre har den laveste kostnaden:

Slette Dupliserader i en SQL Server-tabell
Nå, ved å bruke disse spørsmålene, la oss slette dupliserte verdier fra tabellen. Forenkle prosessen vår, vi bruker bare det andre, det femte og det sjette spørsmålet:
Når du sletter dataene og ser på utførelsesplanene igjen, ser vi at den raskeste er den første SLETT-kommandoen og den tregeste er den siste som forventet:
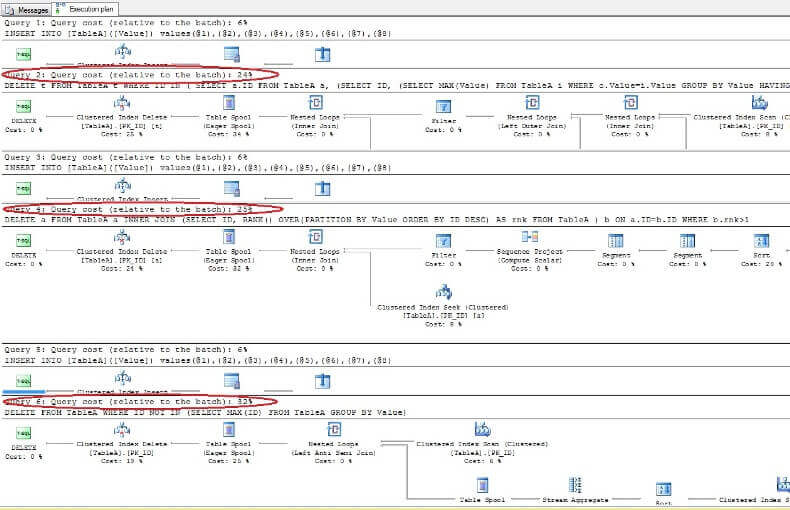
Fjerne duplikater fra tabellen uten en unik indeks i ORACLE
Som et middel til å illustrere vårt siste eksempel i dette tipset, vil jeg forklare noen lignende funksjonalitet i Oracle. rader fra t i stand uten en unik indeks er litt enklere i Oracle enn i SQL Server. Det er en ROWID-pseudokolonne i Oracle som returnerer adressen til raden. Det identifiserer raden i tabellen unikt (vanligvis også i databasen, men i dette tilfellet er det et unntak – hvis forskjellige tabeller lagrer data i samme klynge, kan de ha samme ROWID).Spørringen nedenfor oppretter og setter inn data i tabellen i Oracle-databasen:
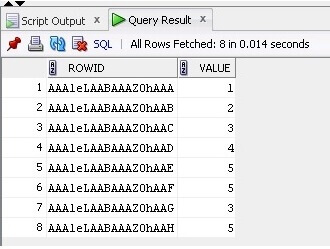
Nå velger vi dataene og ROWID fra tabellen:
SELECT ROWID, Value FROM TableB;
Resultatet er nedenfor:
Nå bruker vi ROWID, vil vi enkelt fjerne dupliserte rader fra tabell:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Vi kan også fjerne duplikater ved å bruke koden nedenfor:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Fjerne duplikater fra en SQL Server-tabell uten en unik indeks
I motsetning til Oracle er det ingen ROWID i SQL Server, så å fjerne duplikater fra tabellen uten en unik indeks vi trenger for å gjøre mer arbeid for å generere unike identifikatorer:
I koden ovenfor lager vi en tabell med dupliserte rader. Vi genererer unike identifikatorer ved hjelp av ROW_NUMBER () -funksjonen, og ved å bruke vanlig tabelluttrykk (CTE) sletter vi duplikater:
Denne koden kan imidlertid erstattes med en mer kompakt og optimal:
Når det er sagt, er det også mulig å identifisere den fysiske adressen til SQL Server for rowin. Til tross for at det er praktisk talt umulig å finne offisiell dokumentasjon om denne funksjonen, kan den brukes som en analog til ROWIDpseudo-kolonnen i Oracle. Det kalles %% physloc %% (siden SQL Server 2008) og det er en virtuell binær (8) kolonne som viser radens fysiske plassering. Ettersom verdien på %% physloc %% er unik for hver rad, kan vi bruke den som en radidentifikator som fjerner dupliserte rader fra en tabell uten en unik indeks. Dermed kan vi fjerne dupliserte rader fra en tabell uten en unik indeks i SQL Server som i Oracleas, som i tilfelle når tabellen har en unik indeks.
De to første spørsmålene nedenfor er tilsvarende versjoner av fjerning av duplikater i Oracle, de neste to er spørsmål for fjerning av duplikater ved bruk av %% physloc %% lignende i tilfelle av tabellen med en unik indeks, og i den siste spørring, %% physloc %% brukes ikke bare for å sammenligne ytelsen til alle disse alternativene:
Når vi analyserer gjennomføringsplanene, kan vi se at de første og siste spørsmålene er raskest sammenlignet med den totale batchen ganger:
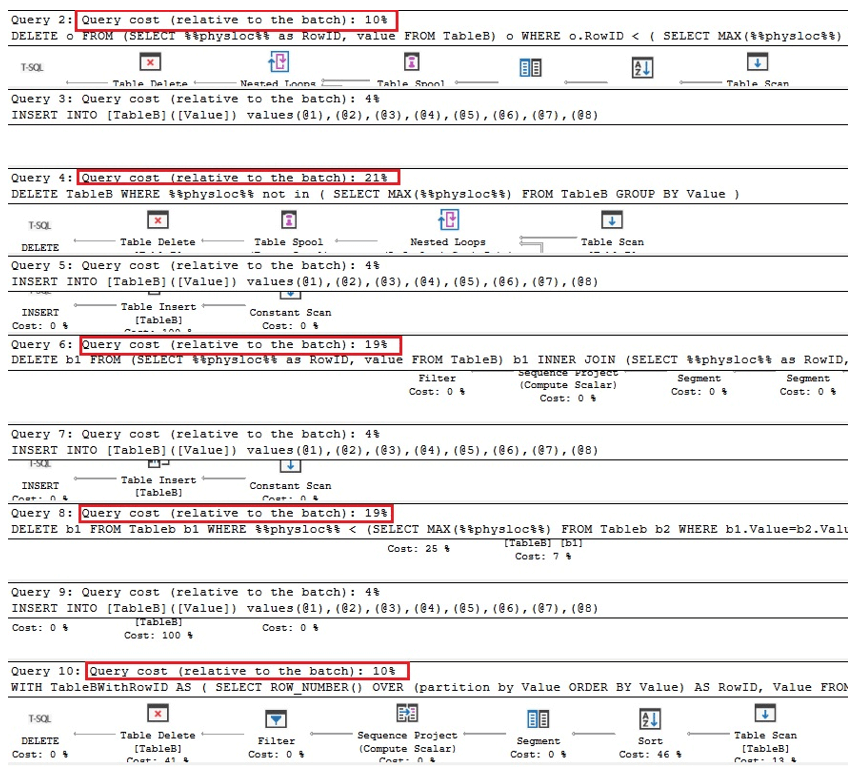
Derfor kan vi konkludere med at bruk av %% physloc %% generelt ikke forbedrer ytelsen. Mens du bruker denne tilnærmingen, er det veldig viktig å innse at dette er en udokumentert funksjon i SQL Server, og derfor bør utviklere være veldig forsiktige.
Det er andre måter å fjerne duplikater på, som ikke er diskutert i dette tipset. For eksempel kan vi lagre forskjellige rader i en midlertidig tabell, deretter slette alle datafra bordet vårt og deretter sette inn forskjellige rader fra midlertidig tabell til vårt permanente bord. I dette tilfellet bør DELETE- og INSERT-setninger inkluderes i en transaksjon.
Konklusjon
I løpet av vår erfaring møter vi situasjoner når vi trenger å rense dupliserte verdier fra SQL Server-tabeller. Dupliseringsverdiene kan være i kolonnen som vil være duplisert basert på våre krav, ellers kan tabellen inneholde dupliserte rader. I begge tilfeller må vi ekskludere dataene for å unngå duplisering av data i databasen. I dette tipset forklarte vi noen teknikker som forhåpentligvis vil være nyttige for å løse disse typer problemer.
Neste trinn
Sist oppdatert: 16.08.2019


Om forfatteren
 Sergey Gigoyan er en databaseprofessor med mer enn 10 års erfaring, med fokus på databasedesign, utvikling, ytelsesjustering, optimalisering, høy tilgjengelighet, BI- og DW-design.
Sergey Gigoyan er en databaseprofessor med mer enn 10 års erfaring, med fokus på databasedesign, utvikling, ytelsesjustering, optimalisering, høy tilgjengelighet, BI- og DW-design. Se alle mine tips
- Flere tips om databaseutviklere …