Rechercher et supprimer les lignes en double dune table SQL Server
Par: Sergey Gigoyan | Mis à jour: 2019-08-16 | Commentaires (11) | En relation: Plus > Conception de base de données
Problème
Selon les bonnes pratiques de databasedesign, une table SQL Server ne doit pas contenir de lignes en double. Au cours du processus de conception de la base de données, des clés primaires doivent être créées pour éliminer les lignes en double. Cependant, nous devons parfois travailler avec des bases de données où ces règles ne sont pas suivies ou des exceptions sont possibles (lorsque ces règles sont ignorées sciemment). Par exemple, lorsquune table intermédiaire est utilisée et que les données sont chargées à partir de différentes sources où des lignes dupliquées sont possibles.Lorsque le processus de chargement est terminé, la table doit être nettoyée ou les données nettoyées doivent être chargées dans une table permanente, donc après cela, les doublons ne sont plus nécessaires. Par conséquent, un problème concernant la suppression des doublons de la table de chargement se pose. Dans cette astuce, examinons quelques moyens de résoudre les besoins de déduplication des données.
Solution
Nous allons considérer deux cas dans cette astuce:
- Le premier cas est celui où une table SQL Server a une clé primaire (ou un index unique) et lune des colonnes contient des valeurs en double qui doivent être supprimées.
- Le deuxième cas est que la table na pas de clé primaire ou tout index unique et contient des lignes en double qui doivent être supprimées. Discutons ces cas séparément.
Comment supprimer les lignes en double dans une table SQL Server
Les enregistrements en double dans une table SQL Server peut être un problème très sérieux. Avec des données en double, il est possible que les commandes soient traitées de nombreuses fois, que les résultats des rapports soient inexacts, etc. Dans SQL Server, il existe un certain nombre de façons de traiter les enregistrements en double dans une table en fonction des circonstances spécifiques telles que:
- Table avec un index unique – Pour les tables avec un index unique, vous avez la possibilité dutiliser lindex pour commander identifier les données en double puis supprimer les enregistrements en double. Lidentification peut être effectuée avec des auto-jointures, en triant les données par la valeur maximale, en utilisant la fonction RANK ou en utilisant la logique NOT IN.
- Table sans index unique – Pour les tables sans index unique, cest un peu plus difficile. Dans ce scénario, la fonction ROW_NUMBER () peut être utilisée avec une expression de table commune (CTE) pour trier les données puis supprimer les enregistrements en double suivants.
Consultez les exemples ci-dessous pour obtenir des exemples concrets sur la suppression des doublons dune table.
Suppression des doublons dune table SQL Server avec un index unique
Configuration de lenvironnement de test
Pour accomplir nos tâches, nous avons besoin dun environnement de test:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Maintenant, insérons des données dans « TableA »:
Comme nous pouvons le voir, les valeurs 3 et 5 existent plusieurs fois dans la colonne « Valeur »:
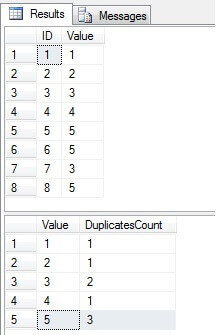
Identifiez les lignes en double dans une table SQL Server
Notre tâche consiste à imposer lunicité de la colonne « Valeur » en supprimant les doublons. La suppression des valeurs en double dune table avec un index unique est un peu plus facile que de supprimer les lignes dune table sans elle. de tous, nous devons trouver des doublons. Il existe de nombreuses façons différentes de le faire. étudier et comparer quelques méthodes courantes.Dans le code ci-dessous, il y a six solutions pour trouver que les valeurs en double qui devraient être supprimées (ne laissant quune seule valeur):
Comme nous pouvons le voir, le résultat pour tous les cas est le même:
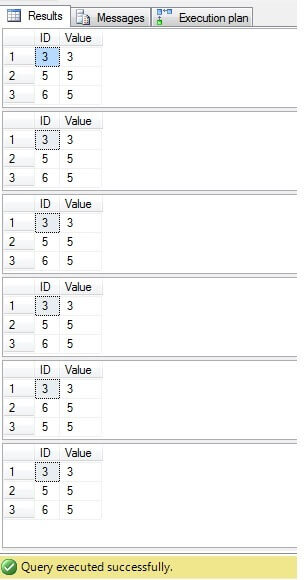
Seules les lignes avec ID = 3, 5, 6 doivent être supprimées. En regardant le plan dexécution, nous pouvons voir que la dernière solution – la solution la plus « compacte » (« Solution 6 ») a un coût le plus élevé (dans notre exemple, il y a une clé primaire sur la colonne « ID », donc les valeurs « NULL » ne sont pas possibles pour cette colonne, donc « NOT IN » fonctionnera sans aucun problème), et la seconde a le coût le plus bas:

Suppression Dupliquer les lignes dans une table SQL Server
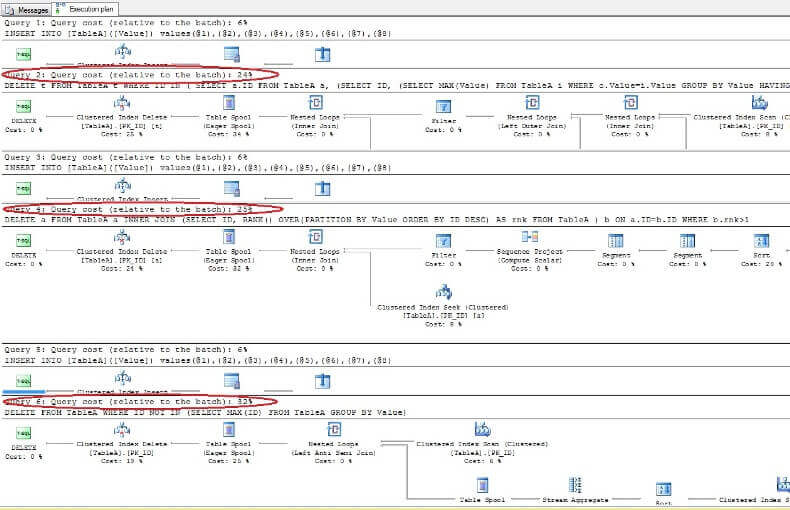
Maintenant, en utilisant ces requêtes, supprimons les valeurs en double de la table. Pour simplifier notre processus, nous nutiliserons que la deuxième, la cinquième et la sixième requêtes:
En supprimant les données et en examinant à nouveau les plans dexécution, nous voyons que la plus rapide est la première commande DELETE et la plus lente est la dernière comme prévu:
Suppression des doublons dune table sans index unique dans ORACLE
Pour illustrer notre dernier exemple dans cette astuce, je souhaite expliquer certaines fonctionnalités similaires dOracle. Suppression des doublons lignes du t capable sans index unique est un peu plus facile dans Oracle que dans SQL Server. Il existe une pseudo-colonne ROWID dans Oracle qui renvoie ladresse de la ligne. Il identifie de manière unique la ligne dans la table (généralement dans la base de données également, mais dans ce cas, il y a une exception – si différentes tables stockent des données dans le même cluster, elles peuvent avoir le même ROWID).La requête ci-dessous crée et insère des données dans la table de la base de données Oracle:
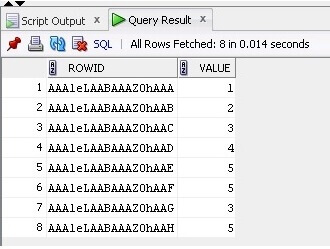
Nous sélectionnons maintenant les données et le ROWID de la table:
SELECT ROWID, Value FROM TableB;
Le résultat est ci-dessous:
Maintenant en utilisant ROWID, nous allons facilement supprimer les lignes en double de table:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Nous pouvons également supprimer les doublons en utilisant le code ci-dessous:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Suppression des doublons dune table SQL Server sans index unique
Contrairement à Oracle, il ny a pas de ROWID dans SQL Server, donc pour supprimer les doublons de la table sans un index unique, nous devons faire un travail supplémentaire pour générer des identifiants uniquerow:
Dans le code ci-dessus, nous créons une table avec des lignes en double. Nous générons des identifiants uniques en utilisant la fonction ROW_NUMBER () et en utilisant lexpression de table commune (CTE), nous supprimons les doublons:
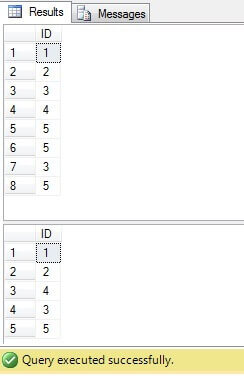
Ce code, cependant, peut être remplacé par un code plus compact et optimal:
Cela dit, il est également possible didentifier ladresse physique du rowin SQL Server. Bien quil soit pratiquement impossible de trouver de la documentation officielle sur cette fonctionnalité, elle peut être utilisée comme une colonne analogique à ROWIDpseudo dans Oracle. Il sappelle %% physloc %% (depuis SQL Server 2008) et il sagit dune colonne binaire virtuelle (8) qui montre lemplacement physique de la ligne. Comme la valeur de %% physloc %% est unique pour chaque ligne, nous pouvons lutiliser comme identifiant de ligne en supprimant les lignes dupliquées dune table sans index unique. Ainsi, nous pouvons supprimer les lignes dupliquées dune table sans index unique dans SQL Server comme dans Oracleas ainsi que dans le cas où la table a un index unique.
Les deux premières requêtes ci-dessous sont les versions équivalentes de la suppression des doublons dans Oracle, les deux suivantes sont des requêtes pour la suppression des doublons en utilisant %% physloc %% similaire au cas de la table avec un index unique, et dans la dernière requête, %% physloc %% nest pas utilisé uniquement pour comparer les performances de toutes ces options:
En analysant les plans dexécution, nous pouvons voir que la première et la dernière requête sont les plus rapides par rapport au lot global fois:
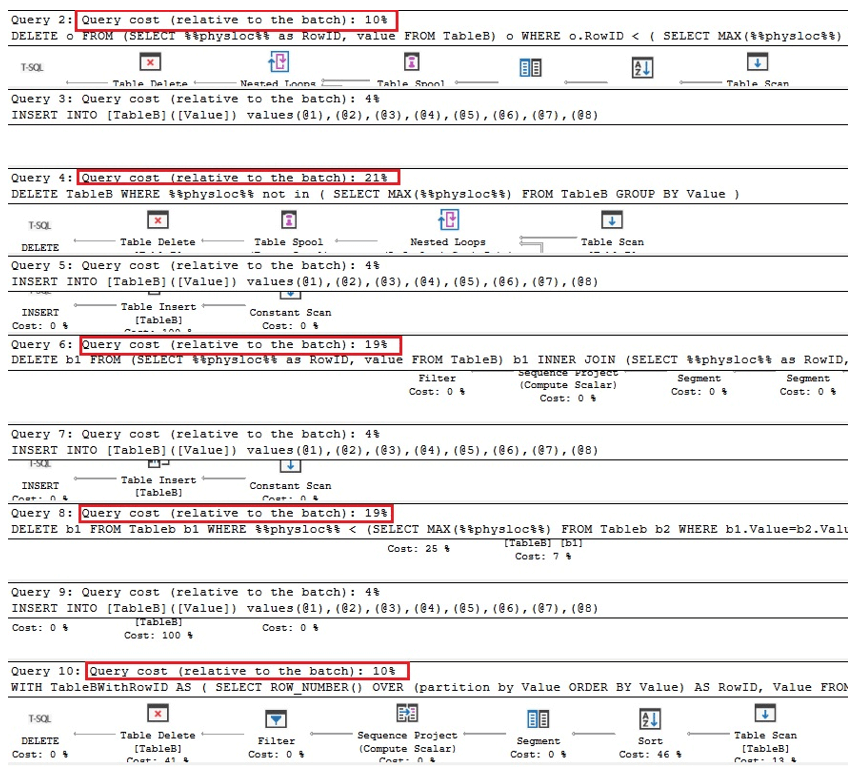
Par conséquent, nous pouvons conclure quen général, lutilisation de %% physloc %% naméliore pas les performances. En utilisant cette approche, il est très important de réaliser quil sagit dune fonctionnalité non documentée de SQL Server et, par conséquent, les développeurs doivent être très prudents.
Il existe dautres moyens de supprimer les doublons qui ne sont pas abordés dans cette astuce. Par exemple, nous pouvons stocker des lignes distinctes dans une table temporaire, puis supprimer toutes les données de notre table et ensuite insérer des lignes distinctes de la table temporaire dans notre table permanente. Dans ce cas, les instructions DELETE et INSERT doivent être incluses dans une transaction.
Conclusion
Au cours de notre expérience, nous sommes confrontés à des situations où nous devons nettoyer les valeurs en double des tables SQL Server. Les valeurs en double peuvent être dans la colonne qui sera dupliquée en fonction de nos besoins ou le tableau peut contenir des lignes en double. Dans les deux cas, nous devons exclure les données pour éviter la duplication des données dans la base de données. Dans cette astuce, nous avons expliqué quelques techniques qui, nous lespérons, seront utiles pour résoudre ces types de problèmes.
Étapes suivantes
Dernière mise à jour: 16/08/2019


À propos de lauteur
 Sergey Gigoyan est un professionnel des bases de données avec plus de 10 ans dexpérience, spécialisé dans la conception, le développement, le réglage des performances, loptimisation, la haute disponibilité, la conception BI et DW.
Sergey Gigoyan est un professionnel des bases de données avec plus de 10 ans dexpérience, spécialisé dans la conception, le développement, le réglage des performances, loptimisation, la haute disponibilité, la conception BI et DW. Voir tout mon astuces
- Autres astuces pour les développeurs de bases de données …