Etsi ja poista päällekkäiset rivit SQL Server -taulukosta
Kirjoittaja: Sergey Gigoyan | Päivitetty: 16.8.2019 | Kommentit (11) Aiheeseen liittyviä: Lisää > Tietokannan suunnittelu
Ongelma
Todellisten tietokantojen suunnittelun parhaiden käytäntöjen mukaan SQL Server -taulukko ei saa sisältää päällekkäisiä rivejä. Tietokannan suunnitteluprosessin aikana tulisi luoda ensisijaiset avaimet päällekkäisten rivien poistamiseksi. Joskus meidän on kuitenkin työskenneltävä tietokantojen kanssa, joissa näitä sääntöjä ei noudateta tai poikkeukset ovat mahdollisia (kun nämä säännöt ohitetaan tietoisesti). Esimerkiksi kun vaiheistustaulukkoa käytetään ja tietoja ladataan eri lähteistä, joissa kaksoisrivit ovat mahdollisia. Kun latausprosessi on valmis, taulukko on puhdistettava tai puhtaat tiedot ladattava pysyvään taulukkoon, joten sen jälkeen kopioita ei enää tarvita. Siksi nousee esiin kaksoiskappaleiden poistaminen lataustaulukosta. Tässä vihjeessä tarkastellaan joitain tapoja ratkaista tietojen kopioinnin tarpeet.
Ratkaisu
Tässä vihjeessä tarkastellaan kahta tapausta:
- Ensimmäinen tapaus on, kun SQL Server -taulukossa on ensisijainen avain (tai yksilöllinen hakemisto) ja yksi sarakkeista sisältää päällekkäisiä arvoja, jotka tulisi poistaa.
- Toinen tapaus on, että taulukossa ei ole ensisijaista avainta tai kaikki yksilölliset hakemistot ja sisältää päällekkäiset rivit, jotka tulisi poistaa. Harkitse tapaukset erikseen.
Kuinka poistaa päällekkäiset rivit SQL Server -taulukossa
Kopioi tietueet SQL Server -taulukko voi olla erittäin vakava ongelma. Päällekkäisten tietojen avulla tilauksia voidaan käsitellä useita kertoja, raportointitulokset ovat virheellisiä ja paljon muuta. SQL Serverissä on useita tapoja korjata kaksoiskappaleet taulukkoon erityisten olosuhteiden perusteella, kuten:
- Taulukko, jossa on yksilöllinen hakemisto – Jos taulukossa on yksilöllinen hakemisto, sinulla on mahdollisuus käyttää hakemisto tilataksesi kaksoiskappaleet, poista sitten kaksoiskappaleet. Tunnistaminen voidaan suorittaa itseliitoksilla, järjestämällä tiedot enimmäisarvon mukaan, käyttämällä RANK-toimintoa tai EI sisään logiikkaa.
- Taulukko ilman yksilöllistä hakemistoa – Jos taulukossa ei ole yksilöllistä hakemistoa, se on vähän enemmän haastava. Tässä skenaariossa funktiota ROW_NUMBER () voidaan käyttää yhteisen taulukon lausekkeen (CTE) kanssa tietojen lajittelemiseen ja seuraavien päällekkäisten tietueiden poistamiseen.
Tutustu alla oleviin esimerkkeihin saadaksesi esimerkkejä todellisesta maailmasta. siitä, kuinka kaksoiskappaleet poistetaan taulukosta.
Päällekkäisten rivien poistaminen yksilöivällä hakemistolla varustetusta SQL Server -taulukosta
Testaa ympäristön määritys
Tehtävien suorittamiseksi tarvitsemme testiympäristön:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Anna nyt lisätä tietoja taulukkoon A:
Kuten voimme nähdä, arvot 3 ja 5 ovat Arvo-sarakkeessa useammin kuin kerran:
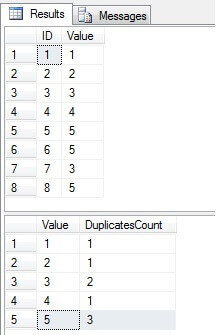
Tunnista päällekkäiset rivit SQL Server -taulukko
Tehtävämme on vahvistaa Arvo-sarakkeen ainutlaatuisuus poistamalla kaksoiskappaleet. Päällekkäisten arvojen poistaminen taulukosta, jolla on yksilöllinen hakemisto, on hieman helpompaa kuin rivien poistaminen taulukosta ilman sitä. kaiken kaikkiaan meidän on löydettävä kaksoiskappaleet. Siihen on monia erilaisia tapoja. Let Tutki ja vertaa joitain yleisiä tapoja. Alla olevassa koodissa on kuusi ratkaisua löytääksesi päällekkäiset arvot, jotka tulisi poistaa (jättäen vain yhden arvon):
Kuten voimme nähdä, kaikkien tapausten tulos on sama:
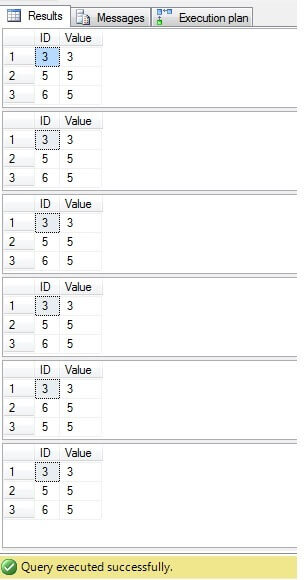
Vain rivit, joiden ID = 3, 5, 6, on poistettava. Suoritussuunnitelmaa tarkasteltaessa voidaan nähdä, että uusin – kaikkein ”pienimmällä” ratkaisulla (”Ratkaisu 6”) on korkeimmat kustannukset (esimerkissämme ID-sarakkeessa on ensisijainen avain, joten ”NULL” -arvot eivät ole mahdollisia sarake, joten ”NOT IN” toimii ilman ongelmia), ja toisella on pienimmät kustannukset:

poistaminen Päällekkäiset rivit SQL Server -taulukossa
Poistetaan nyt näitä kyselyitä käyttämällä päällekkäiset arvot taulukosta. Tosimplifioimme prosessia, käytämme vain toista, viidennestä ja kuudennesta kyselystä:
Poistamalla tiedot ja tarkastelemalla suoritussuunnitelmia näemme, että nopein on ensimmäinen DELETE-komento ja hitain on viimeinen odotetusti:
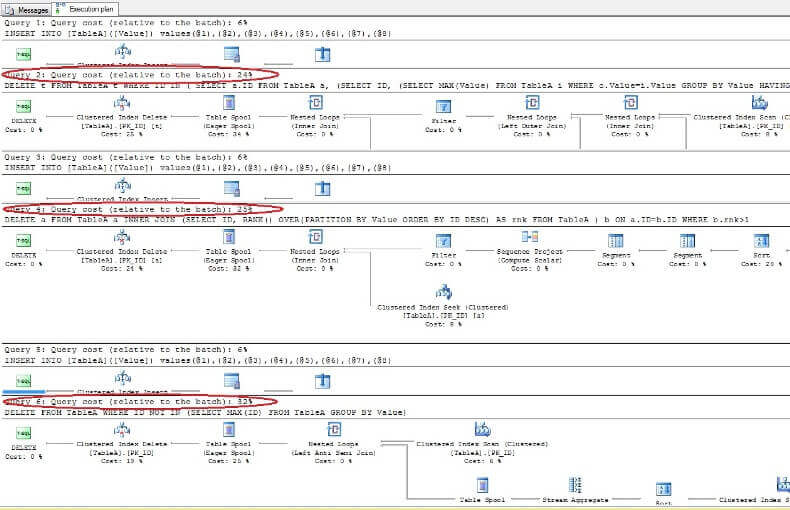
kaksoiskappaleiden poistaminen taulukosta, jolla ei ole yksilöllistä hakemistoa ORACLE-sovelluksessa
Haluan selittää joitain vastaavia toimintoja Oraclessa tämän vihjeen viimeisen esimerkin havainnollistamiseksi. riviä t: stä yksilöllinen hakemisto on hieman helpompaa Oraclessa kuin SQL Serverissä. Oraclessa on ROWID-näennäinen sarake, joka palauttaa rivin osoitteen. Se yksilöi taulukon rivin (yleensä myös tietokannassa, mutta tässä tapauksessa on poikkeus – jos eri taulukot tallentavat tietoja samaan klusteriin, niillä voi olla sama ROWID).Alla oleva kysely luo ja lisää tietoja Oracle-tietokannan taulukkoon:
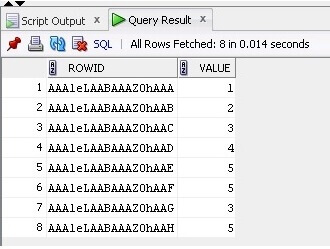
Nyt valitsemme tiedot ja ROWID taulukosta:
SELECT ROWID, Value FROM TableB;
Tulos on alla:
Kun nyt käytetään ROWID: tä, poistamme helposti kaksoisrivit taulukko:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Voimme poistaa myös kaksoiskappaleet alla olevan koodin avulla:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
kaksoiskappaleiden poistaminen SQL Server -taulukosta ilman yksilöllistä hakemistoa
Toisin kuin Oracle, SQL Serverissä ei ole ROWID-tunnusta, joten kaksoiskappaleiden poistaminen taulukosta ilman ainutlaatuinen hakemisto, meidän on tehtävä lisätyötä ainutlaatuisten tunnisteiden luomiseksi:
Yllä olevassa koodissa luomme taulukon, jossa on kaksoisrivit. Luomme ainutkertaisia tunnisteita ROW_NUMBER () -toiminnon avulla ja poistamalla kaksoiskappaleita käyttämällä yhteistä taulukon lauseketta (CTE):
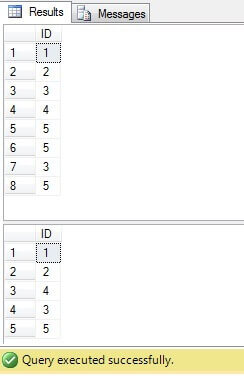
Tämä koodi voidaan kuitenkin korvata pienemmällä ja optimaalisemmalla:
Tämän sanottuaan on mahdollista tunnistaa myös rowin SQL Serverin fyysinen osoite. Huolimatta siitä, että tästä ominaisuudesta on käytännössä mahdotonta löytää virallista dokumentaatiota, sitä voidaan käyttää Oraclen ROWIDpseudo -sarakkeen analogisena. Sitä kutsutaan %% physloc %% (SQL Server 2008: sta lähtien), ja se on virtuaalinen binaarinen (8) sarake, joka näyttää rivin fyysisen sijainnin. Koska %% physloc %% -arvo on yksilöllinen kullekin riville, voimme käyttää sitä rivin tunnisteena, joka poistaa kaksoisrivejä taulukosta ilman yksilöllistä hakemistoa. Siten voimme poistaa päällekkäiset rivit taulukosta ilman yksilöllistä hakemistoa SQL Serverissä kuten Oracleasissa samoin kuin siinä tapauksessa, että taulukolla on ainutlaatuinen hakemisto.
Kaksi ensimmäistä kyselyä ovat vastaavia versioita kaksoiskappaleiden poistamisesta Oraclesta, kaksi seuraavaa ovat kyselyjä kaksoiskappaleiden poistamisesta käyttämällä %% physloc %% similarto -taulukkoa, jolla on yksilöllinen hakemisto, ja viimeisessä kyselyä, %% physloc %% ei käytetä vain kaikkien näiden vaihtoehtojen suorituskyvyn vertaamiseen:
Analysoimalla suoritussuunnitelmia voimme nähdä, että ensimmäinen ja viimeinen kysely ovat nopeimpia verrattuna koko erään kertaa:
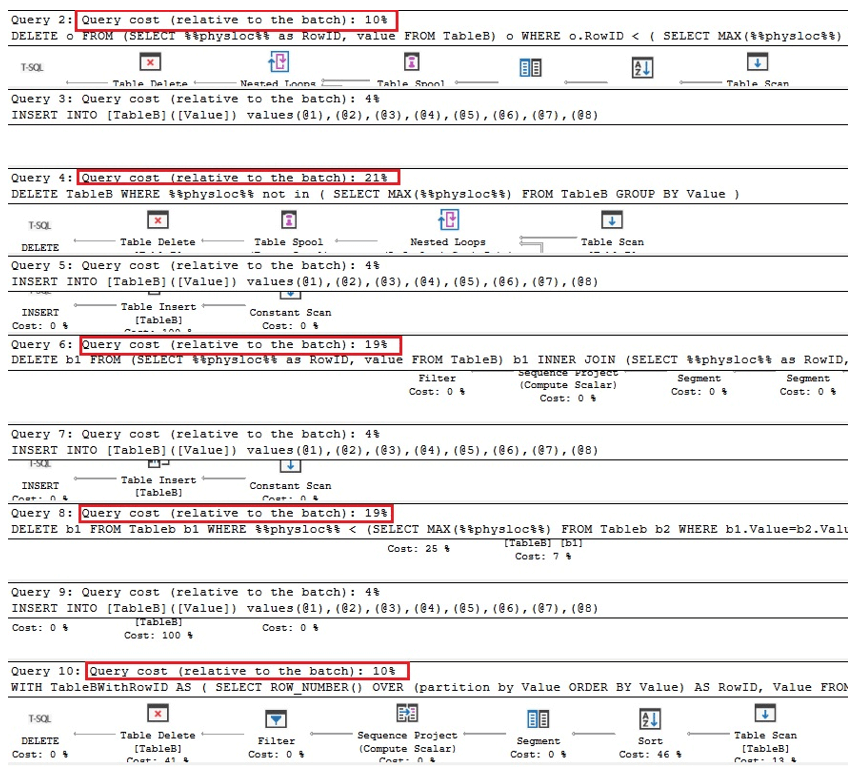
Siksi voimme päätellä, että yleensä %% physloc %%: n käyttö ei paranna suorituskykyä. Tätä lähestymistapaa käytettäessä on erittäin tärkeää ymmärtää, että tämä on SQL Serverin dokumentoimaton ominaisuus, ja siksi kehittäjien tulisi olla erittäin varovaisia.
On olemassa muita tapoja poistaa kaksoiskappaleet, joita ei käsitellä tässä vihjeessä. Esimerkiksi voimme tallentaa erilliset rivit väliaikaiseen taulukkoon, poistaa sitten kaikki taulukon tiedot ja lisätä sen jälkeen erilliset rivit väliaikaisesta taulukosta pysyvään taulukkoon. Tässä tapauksessa DELETE- ja INSERT-lauseet tulisi sisällyttää yhteen tapahtumaan.
Johtopäätös
Kokemuksemme aikana kohtaamme tilanteita, joissa meidän on puhdistettava päällekkäiset arvot SQL Server -taulukoista. Päällekkäiset arvot voivat olla sarakkeessa, joka kopioidaan tarpeidemme perusteella, tai taulukko voi sisältää päällekkäisiä rivejä. Kummassakin tapauksessa meidän on suljettava tiedot pois päällekkäisyyksien välttämiseksi tietokannassa.Tässä vihjeessä selitimme joitain tekniikoita, joista toivottavasti on hyötyä tämäntyyppisten ongelmien ratkaisemisessa. > Viimeksi päivitetty: 16.8.2019


Tietoja kirjoittajasta
 Sergey Gigoyan on tietokannan ammattilainen, jolla on yli 10 vuoden kokemus ja joka keskittyy tietokantojen suunnitteluun, kehittämiseen, suorituskyvyn viritykseen, optimointiin, korkeaan käytettävyyteen, BI- ja DW-suunnitteluun.
Sergey Gigoyan on tietokannan ammattilainen, jolla on yli 10 vuoden kokemus ja joka keskittyy tietokantojen suunnitteluun, kehittämiseen, suorituskyvyn viritykseen, optimointiin, korkeaan käytettävyyteen, BI- ja DW-suunnitteluun. Näytä kaikki omat vinkkejä
- Lisää tietokantakehittäjien vinkkejä …