Buscar y eliminar filas duplicadas de una tabla de SQL Server
Por: Sergey Gigoyan | Actualizado: 2019-08-16 | Comentarios (11) | Relacionado: Más > Diseño de base de datos
Problema
De acuerdo con las mejores prácticas de todatabasedesign, una tabla de SQL Server no debe contener filas duplicadas. Durante el proceso de diseño de la base de datos, se deben crear claves primarias para eliminar filas duplicadas. Sin embargo, a veces necesitamos trabajar con bases de datos en las que estas reglas no se siguen o donde es posible hacer excepciones (cuando estas reglas se omiten a sabiendas). Por ejemplo, cuando se utiliza una tabla de preparación y se cargan datos de diferentes fuentes donde es posible duplicar filas, cuando se completa el proceso de carga, la tabla debe limpiarse o los datos limpios deben cargarse en una tabla permanente, de modo que después de eso ya no se necesiten duplicados. Por tanto, surge un problema relacionado con la eliminación de duplicados de la tabla de carga. En este consejo, examinemos algunas formas de resolver las necesidades de deduplicación de datos.
Solución
Consideraremos dos casos en este consejo:
- El primer caso es cuando una tabla de SQL Server tiene una clave principal (o índice único) y una de las columnas contiene valores duplicados que deben eliminarse.
- El segundo caso es que la tabla no tiene una clave principal o cualquier índice único y contiene filas duplicadas que deben eliminarse. Analicemos estos casos por separado.
Cómo eliminar filas duplicadas en una tabla de SQL Server
Registros duplicados en una tabla de SQL Server puede ser un problema muy serio. Con datos duplicados, es posible que los pedidos se procesen varias veces, tengan resultados inexactos para los informes y más. En SQL Server hay varias formas de direccionar registros duplicados en una tabla en función de circunstancias específicas, tales como:
- Tabla con índice único: para tablas con un índice único, tiene la oportunidad de usar el índice para ordenar identifica los datos duplicados y luego elimine los registros duplicados. La identificación se puede realizar con autouniones, ordenando los datos por el valor máximo, usando la función RANK o usando la lógica NOT IN.
- Tabla sin un índice único – Para tablas sin un índice único, es un poco más desafiante. En este escenario, la función ROW_NUMBER () se puede utilizar con una expresión de tabla común (CTE) para ordenar los datos y luego eliminar los registros duplicados posteriores.
Consulte los ejemplos a continuación para obtener ejemplos del mundo real. sobre cómo eliminar registros duplicados de una tabla.
Eliminar filas duplicadas de una tabla de SQL Server con un índice único
Configuración del entorno de prueba
Para realizar nuestras tareas, necesitamos un entorno de prueba:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Ahora insertemos datos en «TableA»:
Como podemos ver, los valores 3 y 5 existen en la columna «Valor» más de una vez:
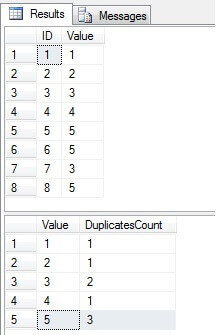
Identificar filas duplicadas en una tabla de SQL Server
Nuestra tarea es imponer la exclusividad de la columna «Valor» eliminando los duplicados. Eliminar los valores duplicados de la tabla con un índice único es un poco más fácil que eliminar las filas de una tabla sin él. Primero de todos, necesitamos encontrar duplicados. Hay muchas formas diferentes de hacerlo. Investigue y compare algunas formas comunes. En el código de abajo hay seis soluciones para encontrar los valores duplicados que deben ser eliminados (dejando solo un valor):
Como podemos ver, el resultado para todos los casos es el mismo:
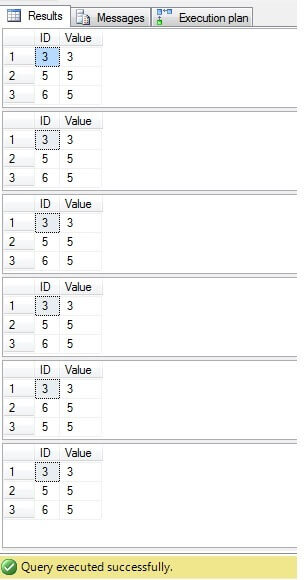
Solo las filas con ID = 3, 5, 6 deben eliminarse. Al observar el plan de ejecución, podemos ver que la última: la solución más «compacta» («Solución 6») tiene un costo más alto (en nuestro ejemplo, hay una clave primaria en la columna «ID», por lo que los valores «NULL» no son posibles para esa columna, por lo tanto, «NOT IN» funcionará sin ningún problema), y la segunda tiene el costo más bajo:

Eliminando Filas duplicadas en una tabla de SQL Server
Ahora, usando estas consultas, eliminemos los valores duplicados de la tabla. Para simplificar nuestro proceso, usaremos solo la segunda, la quinta y la sexta consultas:
Eliminando los datos y mirando nuevamente los planes de ejecución, vemos que el más rápido es el primer comando DELETE y el más lento es el último como se esperaba:
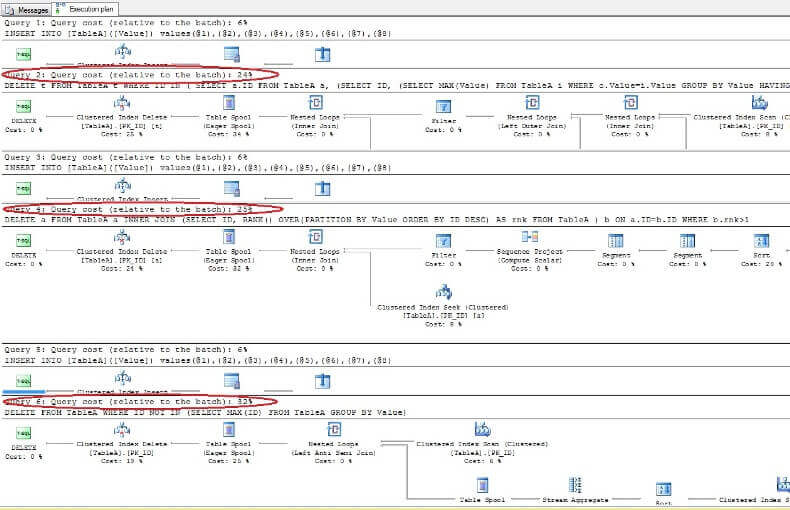
Eliminando duplicados de la tabla sin un índice único en ORACLE
Como un medio para ayudar a ilustrar nuestro ejemplo final en este consejo, quiero explicar algunas funciones similares en Oracle. filas de la t poder sin un índice único es un poco más fácil en Oracle que en SQL Server. Hay una pseudocolumna ROWID en Oracle que devuelve la dirección de la fila. Identifica de forma única la fila en la tabla (generalmente también en la base de datos, pero en este caso, hay una excepción: si diferentes tablas almacenan datos en el mismo clúster, pueden tener el mismo ROWID).La consulta a continuación crea e inserta datos en la tabla en la base de datos de Oracle:
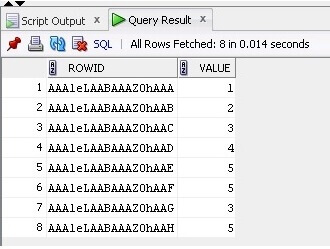
Ahora estamos seleccionando los datos y ROWID de la tabla:
SELECT ROWID, Value FROM TableB;
El resultado es el siguiente:
Ahora, usando ROWID, eliminaremos fácilmente las filas duplicadas de table:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
También podemos eliminar duplicados usando el siguiente código:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Eliminación de duplicados de una tabla de SQL Server sin un índice único
A diferencia de Oracle, no hay ROWID en SQL Server, por lo que para eliminar duplicados de la tabla sin un índice único, necesitamos hacer un trabajo adicional para generar identificadores de fila únicos:
En el código anterior, estamos creando una tabla con filas duplicadas. Estamos generando identificadores únicos usando la función ROW_NUMBER () y usando la expresión de tabla común (CTE) estamos eliminando duplicados:
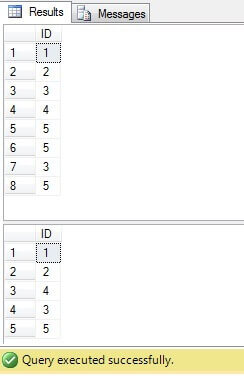
Este código, sin embargo, se puede reemplazar por uno más compacto y óptimo:
Dicho esto, también es posible identificar la dirección física del servidor SQL de rowin. A pesar de que es prácticamente imposible encontrar documentación oficial sobre esta característica, se puede utilizar como análogo a la columna ROWIDpseudo en Oracle. Se llama %% physloc %% (desde SQL Server 2008) y es una columna virtual binaria (8) que muestra la ubicación física de la fila. Como el valor de %% physloc %% es único para cada fila, podemos usarlo como un identificador de fila mientras eliminamos filas duplicadas de una tabla sin un índice único. Por lo tanto, podemos eliminar filas duplicadas de una tabla sin un índice único en SQL Server como en Oracle, así como en el caso en que la tabla tiene un índice único.
Las dos primeras consultas a continuación son las versiones equivalentes de eliminar duplicados en Oracle, las dos siguientes son consultas para eliminar duplicados usando %% physloc %% similar al caso de la tabla con un índice único, y en la última consulta, %% physloc %% no se usa solo para comparar el rendimiento de todas estas opciones:
Al analizar los planes de ejecución, podemos ver que la primera y la última consulta son las más rápidas en comparación con el lote general veces:
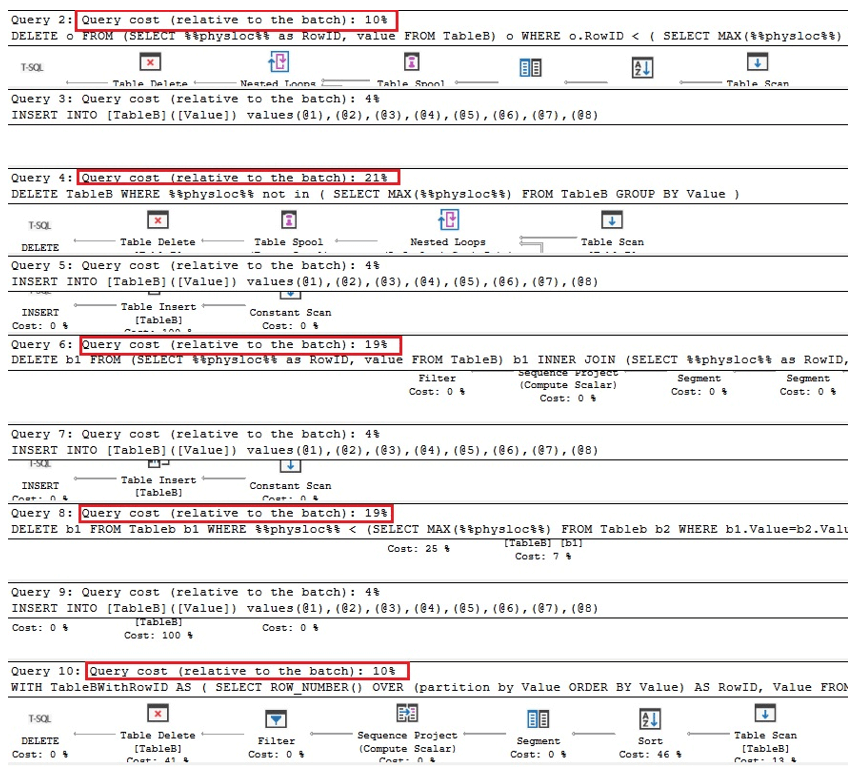
Por tanto, podemos concluir que, en general, utilizar %% physloc %% no mejora el rendimiento. Al usar este enfoque, es muy importante darse cuenta de que esta es una característica no documentada de SQL Server y, por lo tanto, los desarrolladores deben tener mucho cuidado.
Hay otras formas de eliminar duplicados que no se describen en este consejo. Por ejemplo, podemos almacenar distintas filas en una tabla temporal, luego eliminar todos los datos de nuestra tabla y luego insertar distintas filas de la tabla temporal en nuestra tabla permanente. En este caso, las declaraciones DELETE e INSERT deben incluirse en una transacción.
Conclusión
Durante nuestra experiencia nos enfrentamos a situaciones en las que necesitamos limpiar valores duplicados de tablas de SQL Server. Los valores duplicados pueden estar en la columna que se duplicará según nuestros requisitos o la tabla puede contener filas duplicadas. En cualquier caso, debemos excluir los datos para evitar la duplicación de datos en la base de datos. En este consejo explicamos algunas técnicas que esperamos sean útiles para resolver este tipo de problemas.
Próximos pasos
Última actualización: 2019-08-16


Acerca del autor
 Sergey Gigoyan es un profesional de bases de datos con más de 10 años de experiencia, con un enfoque en el diseño, desarrollo, ajuste de rendimiento, optimización, alta disponibilidad, diseño BI y DW de bases de datos.
Sergey Gigoyan es un profesional de bases de datos con más de 10 años de experiencia, con un enfoque en el diseño, desarrollo, ajuste de rendimiento, optimización, alta disponibilidad, diseño BI y DW de bases de datos. Ver todos mis tips
- Más sugerencias para desarrolladores de bases de datos …