Hitta och ta bort duplicerade rader från en SQL Server-tabell
Av: Sergey Gigoyan | Uppdaterad: 2019-08-16 | Kommentarer (11) | Relaterat: Mer > Databasdesign
Problem
Enligt databasdesign bästa metoder bör en SQL Server-tabell inte innehålla dubbla rader. Under databasdesignprocessen bör primärnycklar skapas för att eliminera dubbla rader. Ibland behöver vi dock arbeta med databaser där dessa regler inte följs eller undantag är möjliga (när dessa regler medvetet kringgås). Till exempel när en iscensättningstabell används och data laddas från olika källor där dubbla rader är möjliga. När laddningsprocessen är klar bör tabellen rengöras eller ren data bör laddas till en permanent tabell, så efter det behövs inte längre dubbletter. Därför uppstår en fråga om borttagning av dubbletter från laddningstabellen. I det här tipset kan vi undersöka några sätt att lösa behov av av duplicering av data.
Lösning
Vi kommer att överväga två fall i detta tips:
- Det första fallet är när en SQL Server-tabell har en primär nyckel (eller unikt index) och en av kolumnerna innehåller dubbla värden som ska tas bort.
- Det andra fallet är att tabellen inte har en primär nyckel eller några unika index och innehåller dubbla rader som ska tas bort. Låt oss diskutera dessa fall separat.
Hur man tar bort dubbletterader i en SQL Server-tabell
Duplicera poster i en SQL Server-tabell kan vara en mycket allvarlig fråga. Med dubbla data är det möjligt för order att behandlas flera gånger, ha felaktiga resultat för rapportering och mer. I SQL Server finns det ett antal sätt att adressera dubbla poster i en tabell baserat på de specifika omständigheterna, till exempel:
- Tabell med unikt index – För tabeller med ett unikt index har du möjligheten att använda indexet för att beställa identifiera duplikatdata och ta sedan bort duplicaterecords. Identifiering kan utföras med självanslutningar, ordning av data efter maxvärdet, med RANK-funktionen eller med NOT IN-logik.
- Tabell utan ett unikt index – För tabeller utan ett unikt index är det lite mer utmanande. I det här scenariot kan funktionen ROW_NUMBER () användas med ett gemensamt tabelluttryck (CTE) för att sortera data och sedan ta bort efterföljande duplikatposter.
Kolla in exemplen nedan för att få verkliga världsexempel om hur man tar bort duplicaterecords från en tabell.
Ta bort dubbletterader från en SQL Server-tabell med ett unikt index
Testmiljöinställning
För att utföra våra uppgifter, vi behöver en testmiljö:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Låt oss nu infoga data i ”TableA”:
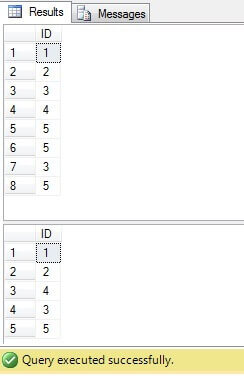
Som vi kan se finns värdena 3 och 5 i kolumnen ”Värde” mer än en gång:
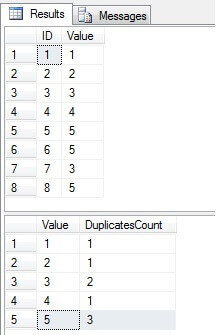
Identifiera duplicerade rader i en SQL Server-tabell
Vår uppgift är att genomdriva unika egenskaper för kolumnen ”Värde” genom att ta bort dubbletter. Att ta bort dubblettvärden från tabellen med ett unikt index är lite enklare än att ta bort raderna från en tabell utan den. av allt måste vi hitta dubbletter. Det finns många olika sätt att göra det. Låt oss undersöka och jämföra några vanliga sätt. I koden nedan finns sex lösningar för att hitta att dubbla värden som ska raderas (lämnar bara ett värde):
Som vi kan se är resultatet för alla fall detsamma:
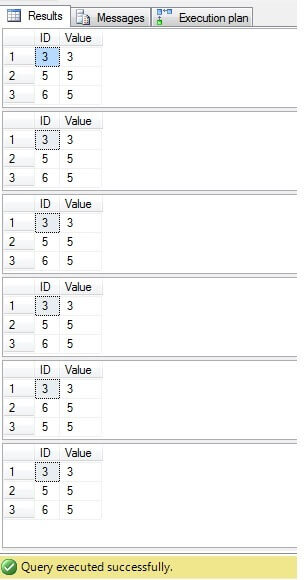
Endast rader med ID = 3, 5, 6 behöver raderas. När vi tittar på körplanen kan vi se att den senaste – den mest ”kompakta” lösningen (”Lösning 6”) har högsta kostnad (i vårt exempel finns det en primär nyckel i kolumnen ”ID”, så ”NULL” -värden är inte möjliga den kolumnen fungerar därför ”INTE IN” utan problem) och den andra har lägsta kostnad:

Radering Duplicera rader i en SQL Server-tabell
Nu, med hjälp av dessa frågor, låt oss ta bort dubblettvärden från tabellen. Förenkla vår process, vi använder bara den andra, den femte och den sjätte frågan:
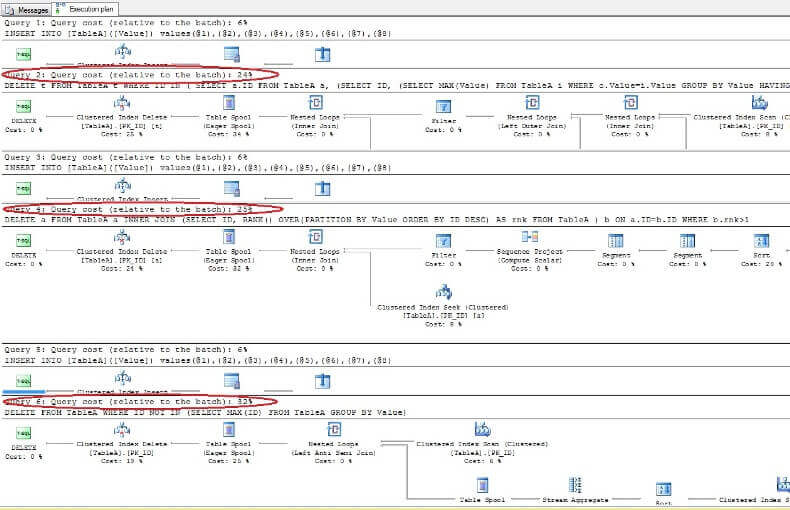
Om vi tar bort data och tittar igenom exekveringsplanerna ser vi att snabbast är det första DELETE-kommandot och det långsammaste är det sista som förväntat:
Ta bort dubbletter från tabellen utan ett unikt index i ORACLE
Som ett sätt att illustrera vårt sista exempel i detta tips vill jag förklara en liknande funktionalitet i Oracle. rader från t utan ett unikt index är lite enklare i Oracle än i SQL Server. Det finns en ROWID-pseudokolumn i Oracle som returnerar radens adress. Det identifierar unikt raden i tabellen (vanligtvis också i databasen, men i det här fallet finns det ett undantag – om olika tabeller lagrar data i samma kluster kan de ha samma ROWID).Frågan nedan skapar och infogar data i tabellen i Oracle-databasen:
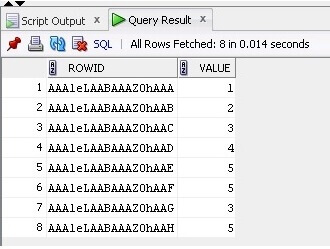
Nu väljer vi data och ROWID från tabellen:
SELECT ROWID, Value FROM TableB;
Resultatet är nedan:
Nu med ROWID tar vi enkelt bort dubbla rader från tabell:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Vi kan också ta bort dubbletter med koden nedan:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Ta bort dubbletter från en SQL Server-tabell utan ett unikt index
Till skillnad från Oracle finns det ingen ROWID i SQL Server, så att ta bort dubbletter från tabellen utan ett unikt index vi behöver göra ytterligare arbete för att skapa unika identifierare:
I koden ovan skapar vi en tabell med dubbla rader. Vi genererar unika identifierare med ROW_NUMBER () -funktionen och genom att använda gemensamt tabelluttryck (CTE) tar vi bort dubbletter:
Den här koden kan dock ersättas med en mer kompakt och optimal:
Med detta sagt är det också möjligt att identifiera den fysiska adressen till SQL Server för rowin. Trots att det är praktiskt taget omöjligt att hitta officiell dokumentation om den här funktionen kan den användas som en analog till ROWIDpseudo-kolumnen i Oracle. Det kallas %% physloc %% (sedan SQL Server 2008) och det är en virtuell binär (8) kolumn som visar radens fysiska plats. Eftersom värdet på %% physloc %% är unikt för varje rad kan vi använda det som en radidentifierare som tar bort dubbla rader från en tabell utan ett unikt index. Således kan vi ta bort duplicerade rader från en tabell utan ett unikt index i SQL Server som i Oracleas, liksom i fallet när tabellen har ett unikt index.
De två första frågorna nedan är motsvarande versioner av att ta bort dubbletter i Oracle, de nästa två är frågor för att ta bort dubbletter med %% physloc %% lik i fallet med tabellen med ett unikt index, och i det sista fråga, %% physloc %% används inte bara för att jämföra prestanda för alla dessa alternativ:
När vi analyserar exekveringsplanerna kan vi se att de första och sista frågorna är snabbast jämfört med den totala batchen gånger:
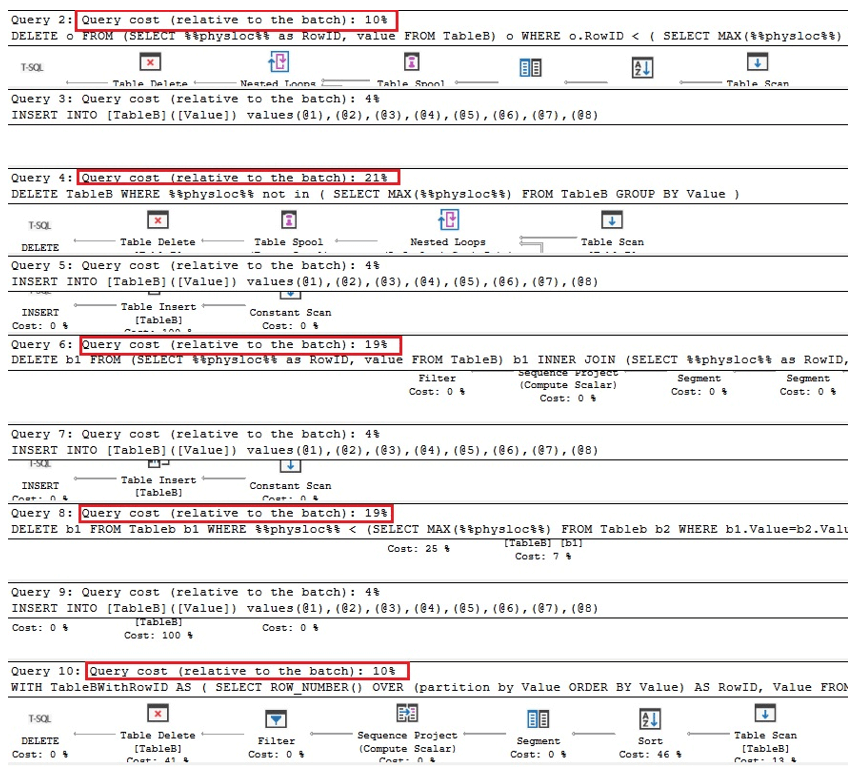
Därför kan vi dra slutsatsen att användning av %% physloc %% i allmänhet inte förbättrar prestanda. När du använder detta tillvägagångssätt är det mycket viktigt att inse att detta är en odokumenterad funktion i SQL Server och därför bör utvecklare vara mycket försiktiga.
Det finns andra sätt att ta bort dubbletter som inte diskuteras i detta tips. Vi kan till exempel lagra distinkta rader i en tillfällig tabell och sedan ta bort alla data från vår tabell och infoga därefter distinkta rader från tillfällig tabell till vår permanenta tabell. I det här fallet bör DELETE- och INSERT-uttalanden ingå i en transaktion.
Slutsats
Under vår erfarenhet står vi inför situationer när vi behöver rensa dubbla värden från SQL Server-tabeller. Dubblettvärdena kan finnas i kolumnen som kommer att dubbla dubbla baserat på våra krav eller så kan tabellen innehålla dubbla rader. I båda fallen måste vi utesluta uppgifterna för att undvika duplicering av data i databasen. I det här tipset förklarade vi några tekniker som förhoppningsvis kommer att vara till hjälp för att lösa dessa typer av problem.
Nästa steg
Senast uppdaterad: 2019-08-16


Om författaren
 Sergey Gigoyan är en databasproffs med mer än tio års erfarenhet, med fokus på databasdesign, utveckling, prestandajustering, optimering, hög tillgänglighet, BI- och DW-design.
Sergey Gigoyan är en databasproffs med mer än tio års erfarenhet, med fokus på databasdesign, utveckling, prestandajustering, optimering, hög tillgänglighet, BI- och DW-design. Visa alla mina tips
- Fler databasutvecklare tips …