Suchen und Entfernen doppelter Zeilen aus einer SQL Server-Tabelle
Von: Sergey Gigoyan | Aktualisiert: 2019-08-16 | Anmerkungen (11) | Verwandte Themen: Weitere > Datenbankdesign
Problem
Gemäß den Best Practices für das Datenbankdesign sollte eine SQL Server-Tabelle keine doppelten Zeilen enthalten. Während des Datenbankentwurfs sollten Primärschlüssel erstellt werden, um doppelte Zeilen zu entfernen. Manchmal müssen wir jedoch mit Datenbanken arbeiten, in denen diese Regeln nicht befolgt werden oder Ausnahmen möglich sind (wenn diese Regeln wissentlich umgangen werden). Wenn beispielsweise eine Staging-Tabelle verwendet wird und Daten aus verschiedenen Quellen geladen werden, in denen doppelte Zeilen möglich sind. Wenn der Ladevorgang abgeschlossen ist, sollte die Tabelle bereinigt oder saubere Daten in eine permanente Tabelle geladen werden, sodass danach keine Duplikate mehr benötigt werden. Daher tritt ein Problem hinsichtlich der Entfernung von Duplikaten aus der Ladetabelle auf. In diesem Tipp werden einige Möglichkeiten zur Lösung von Deduplizierungsanforderungen für Daten untersucht.
Lösung
In diesem Tipp werden zwei Fälle betrachtet:
- Der erste Fall ist, wenn eine SQL Server-Tabelle einen Primärschlüssel (oder einen eindeutigen Index) hat und eine der Spalten doppelte Werte enthält, die entfernt werden sollten.
- Der zweite Fall ist, dass die Tabelle keinen Primärschlüssel hat oder eindeutige Indizes und enthält doppelte Zeilen, die entfernt werden sollten. Lassen Sie uns diese Fälle separat behandeln.
So entfernen Sie doppelte Zeilen in einer SQL Server-Tabelle
Doppelte Datensätze in Eine SQL Server-Tabelle kann ein sehr ernstes Problem sein. Mit doppelten Daten ist es möglich, dass Bestellungen mehrfach verarbeitet werden, ungenaue Ergebnisse für die Berichterstellung vorliegen und vieles mehr. In SQL Server gibt es eine Reihe von Möglichkeiten, doppelte Datensätze in einer Tabelle basierend auf den spezifischen Umständen zu adressieren, z. B.:
- Tabelle mit eindeutigem Index – Für Tabellen mit einem eindeutigen Index haben Sie die Möglichkeit, diese zu verwenden Der zu bestellende Index identifiziert die doppelten Daten und entfernt dann die doppelten Datenaufzeichnungen. Die Identifizierung kann mit Self-Joins erfolgen, wobei die Daten nach dem Maximalwert geordnet werden, die RANK-Funktion verwendet wird oder die NOT IN-Logik verwendet wird.
- Tabelle ohne eindeutigen Index – Bei Tabellen ohne eindeutigen Index ist dies etwas mehr herausfordernd. In diesem Szenario kann die Funktion ROW_NUMBER () mit einem allgemeinen Tabellenausdruck (CTE) verwendet werden, um die Daten zu sortieren und anschließend die nachfolgenden doppelten Datensätze zu löschen.
Sehen Sie sich die folgenden Beispiele an, um Beispiele aus der Praxis zu erhalten Informationen zum Löschen von doppelten Aufzeichnungen aus einer Tabelle.
Entfernen doppelter Zeilen aus einer SQL Server-Tabelle mit einem eindeutigen Index
Setup der Testumgebung
Um unsere Aufgaben auszuführen, Wir benötigen eine Testumgebung:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Fügen wir nun Daten in „TableA“ ein:
Wie wir sehen können, sind die Werte 3 und 5 in der Spalte „Wert“ mehrmals vorhanden:
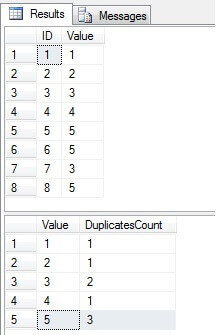
Identifizieren Sie doppelte Zeilen in Eine SQL Server-Tabelle
Unsere Aufgabe besteht darin, die Eindeutigkeit der Spalte „Wert“ durch Entfernen von Duplikaten zu erzwingen. Das Entfernen doppelter Werte aus einer Tabelle mit einem eindeutigen Index ist etwas einfacher als das Entfernen der Zeilen aus einer Tabelle ohne diesen von allen müssen wir Duplikate finden. Es gibt viele verschiedene Möglichkeiten, dies zu tun. Lassen Sie uns Untersuchen und vergleichen Sie einige gängige Methoden. Im folgenden Code gibt es sechs Lösungen, um die doppelten Werte zu finden, die gelöscht werden sollten (wobei nur ein Wert übrig bleibt):
Wie wir sehen können, ist das Ergebnis für alle Fälle das gleiche:
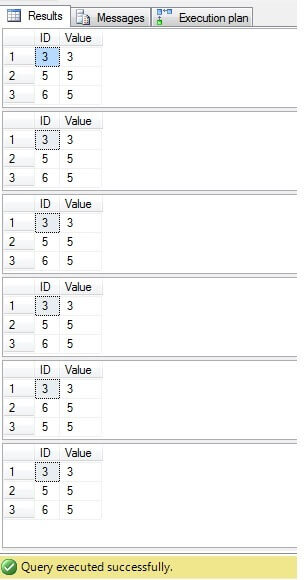
Es müssen nur Zeilen mit der ID = 3, 5, 6 gelöscht werden. Wenn Sie sich den Ausführungsplan ansehen, können Sie feststellen, dass die neueste – die „kompakteste“ Lösung („Lösung 6“) die höchsten Kosten verursacht (in unserem Beispiel befindet sich ein Primärschlüssel in der Spalte „ID“, sodass „NULL“ -Werte nicht möglich sind Diese Spalte, daher „NOT IN“, funktioniert problemlos), und die zweite Spalte hat die niedrigsten Kosten:

Löschen Doppelte Zeilen in einer SQL Server-Tabelle
Löschen Sie nun mithilfe dieser Abfragen doppelte Werte aus der Tabelle. Um unseren Prozess zu vereinfachen, verwenden wir nur die zweite, die fünfte und die sechste Abfrage:
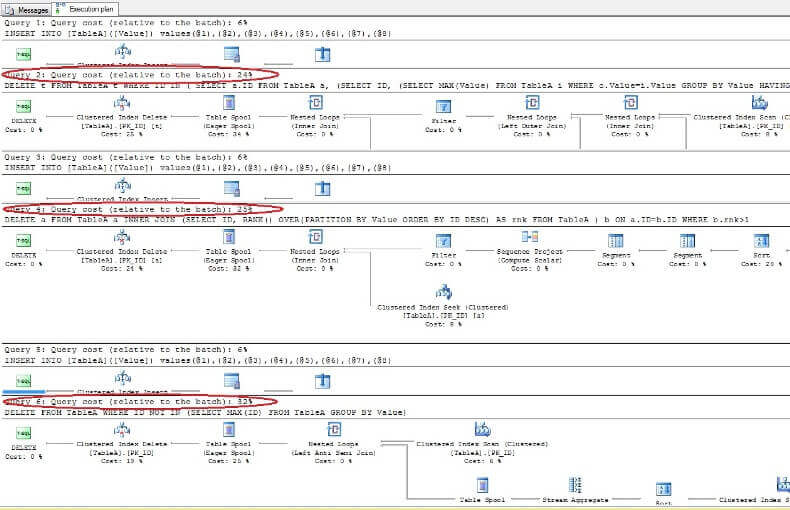
Wenn Sie die Daten löschen und erneut in die Ausführungspläne schauen, sehen Sie, dass der schnellste der erste DELETE-Befehl und der langsamste wie erwartet der letzte ist:
Entfernen von Duplikaten aus einer Tabelle ohne eindeutigen Index in ORACLE
Um unser letztes Beispiel in diesem Tipp zu veranschaulichen, möchte ich einige ähnliche Funktionen in Oracle erläutern. Entfernen von Duplikaten Zeilen aus dem t Ohne einen eindeutigen Index ist dies in Oracle etwas einfacher als in SQL Server. In Oracle gibt es eine ROWID-Pseudospalte, die die Adresse der Zeile zurückgibt. Es identifiziert die Zeile in der Tabelle eindeutig (normalerweise auch in der Datenbank, aber in diesem Fall gibt es eine Ausnahme – wenn verschiedene Tabellen Daten in demselben Cluster speichern, können sie dieselbe ROWID haben).Die folgende Abfrage erstellt Daten und fügt sie in die Tabelle in der Oracle-Datenbank ein:
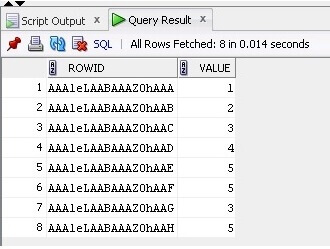
Jetzt wählen wir die Daten und die ROWID aus der Tabelle aus:
SELECT ROWID, Value FROM TableB;
Das Ergebnis ist unten:
Mit ROWID können wir jetzt problemlos doppelte Zeilen aus entfernen Tabelle:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Wir können Duplikate auch mit dem folgenden Code entfernen:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Entfernen von Duplikaten aus einer SQL Server-Tabelle ohne eindeutigen Index
Im Gegensatz zu Oracle gibt es in SQL Server keine ROWID, sodass Duplikate ohne aus der Tabelle entfernt werden können Für einen eindeutigen Index müssen wir zusätzliche Arbeit leisten, um eindeutige Bezeichner zu generieren:
Im obigen Code erstellen wir eine Tabelle mit doppelten Zeilen. Wir generieren eindeutige Bezeichner mit der Funktion ROW_NUMBER () und löschen mithilfe des Common Table Expression (CTE) Duplikate:
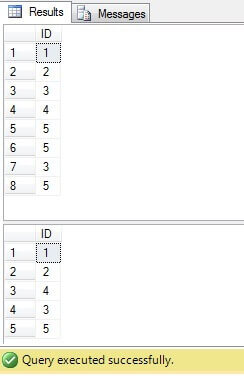
Dieser Code kann jedoch durch einen kompakteren und optimaleren Code ersetzt werden:
Allerdings ist es auch möglich, die physische Adresse des Rowin SQL Server zu identifizieren. Trotz der Tatsache, dass es praktisch unmöglich ist, eine offizielle Dokumentation zu dieser Funktion zu finden, kann sie in Oracle als Analog zur ROWIDpseudo-Spalte verwendet werden. Es heißt %% physloc %% (seit SQL Server 2008) und ist eine virtuelle Binärspalte (8), die den physischen Speicherort der Zeile anzeigt. Da der Wert von %% physloc %% für jede Zeile eindeutig ist, können wir ihn als Zeilenbezeichner verwenden, während doppelte Zeilen aus einer Tabelle ohne eindeutigen Index entfernt werden. Auf diese Weise können wir doppelte Zeilen aus einer Tabelle ohne eindeutigen Index in SQL Server entfernen, wie in Oracleas und wie in dem Fall, in dem die Tabelle einen eindeutigen Index hat.
Die ersten beiden Abfragen sind die entsprechenden Versionen zum Entfernen von Duplikaten in Oracle. Die nächsten beiden sind Abfragen zum Entfernen von Duplikaten mit %% physloc %% ähnlich wie bei der Tabelle mit einem eindeutigen Index und in der letzten Abfrage, %% physloc %% wird nicht nur zum Vergleichen der Leistung all dieser Optionen verwendet:
Bei der Analyse der Ausführungspläne können wir feststellen, dass die erste und die letzte Abfrage im Vergleich zum Gesamtstapel am schnellsten sind Zeiten:
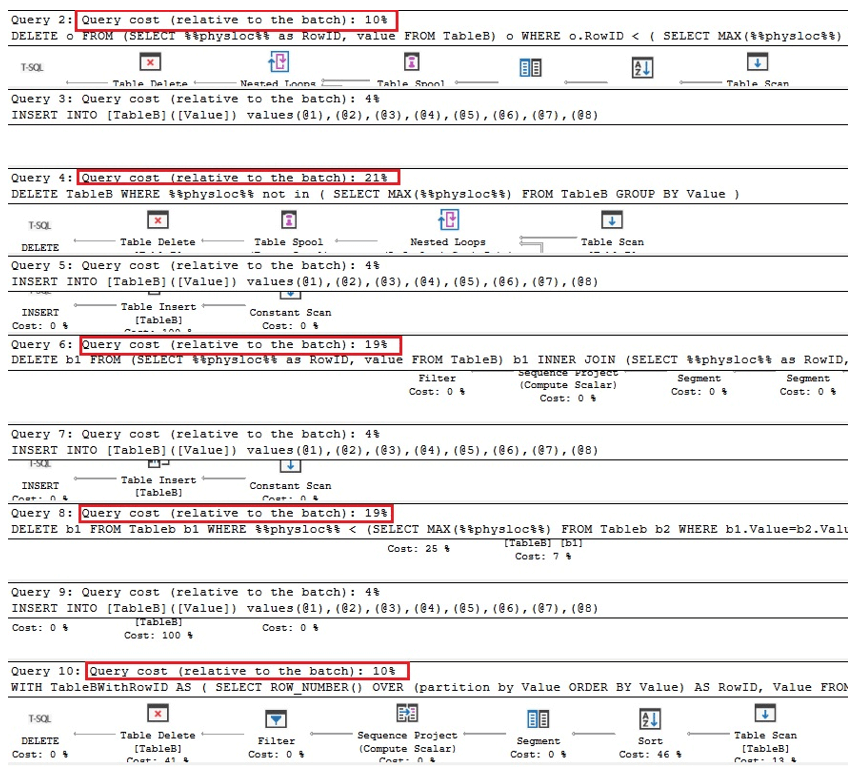
Daher können wir schließen, dass die Verwendung von %% physloc %% im Allgemeinen die Leistung nicht verbessert. Bei Verwendung dieses Ansatzes ist es sehr wichtig zu wissen, dass dies eine undokumentierte Funktion von SQL Server ist. Daher sollten Entwickler sehr vorsichtig sein.
Es gibt andere Möglichkeiten, Duplikate zu entfernen, die in diesem Tipp nicht behandelt werden. Beispielsweise können wir unterschiedliche Zeilen in einer temporären Tabelle speichern, dann alle Daten aus unserer Tabelle löschen und anschließend unterschiedliche Zeilen aus der temporären Tabelle in unsere permanente Tabelle einfügen. In diesem Fall sollten die Anweisungen DELETE und INSERT in einer Transaktion enthalten sein.
Schlussfolgerung
Nach unserer Erfahrung treten Situationen auf, in denen doppelte Werte aus SQL Server-Tabellen entfernt werden müssen. Die doppelten Werte können sich in der Spalte befinden, die gemäß unseren Anforderungen dupliziert wird, oder die Tabelle kann doppelte Zeilen enthalten. In beiden Fällen müssen wir die Daten ausschließen, um eine Duplizierung der Daten in der Datenbank zu vermeiden. In diesem Tipp haben wir einige Techniken erläutert, die hoffentlich hilfreich sind, um diese Arten von Problemen zu lösen.
Nächste Schritte
Letzte Aktualisierung: 16.08.2019


Über den Autor
 Sergey Gigoyan ist ein Datenbankprofi mit mehr als 10 Jahren Erfahrung, mit Schwerpunkt auf Datenbankdesign, Entwicklung, Leistungsoptimierung, Optimierung, Hochverfügbarkeit, BI- und DW-Design.
Sergey Gigoyan ist ein Datenbankprofi mit mehr als 10 Jahren Erfahrung, mit Schwerpunkt auf Datenbankdesign, Entwicklung, Leistungsoptimierung, Optimierung, Hochverfügbarkeit, BI- und DW-Design. Alle meine anzeigen Tipps
- Weitere Tipps für Datenbankentwickler …