Găsiți și eliminați rânduri duplicate dintr-un tabel SQL Server
De: Sergey Gigoyan | Actualizat: 16.08.2019 | Comentarii (11) | Corelat: Mai multe > Proiectarea bazei de date
Problemă
Conform celor mai bune practici de proiectare, un tabel SQL Server nu trebuie să conțină rânduri duplicate. În timpul procesului de proiectare a bazei de date ar trebui create chei primare pentru a elimina rândurile duplicate. Cu toate acestea, uneori trebuie să lucrăm cu baze de date în care aceste reguli nu sunt respectate sau sunt posibile excepții (când aceste reguli sunt ocolite cu bună știință). De exemplu, atunci când se folosește o masă de etapizare și se încarcă date din diferite surse, unde sunt posibile rânduri duplicate. Când procesul de încărcare se încheie, tabelul trebuie curățat sau datele curate ar trebui încărcate într-un tabel permanent, astfel încât după aceea nu mai sunt necesare duplicate. Prin urmare, apare o problemă privind eliminarea duplicatelor din tabelul de încărcare. Acest sfat să examinăm câteva modalități de a rezolva nevoile de duplicare a datelor.
Soluție
Vom lua în considerare două cazuri în acest sfat:
- Primul caz este atunci când un tabel SQL Server are o cheie primară (sau un index unic) și una dintre coloane conține valori duplicat care ar trebui eliminate.
- Al doilea caz este că tabelul nu are o cheie primară sau orice index unic și conține rânduri duplicate care ar trebui eliminate. Să discutăm aceste cazuri separat.
Cum se elimină rândurile duplicate dintr-un tabel SQL Server
Înregistrări duplicate în un tabel SQL Server poate fi o problemă foarte gravă. Cu date duplicate, este posibil ca comenzile să fie procesate de mai multe ori, să aibă rezultate inexacte pentru raportare și multe altele. În SQL Server există o serie de moduri de a adresa înregistrări duplicate într-un tabel pe baza circumstanțelor specifice, cum ar fi:
- Tabel cu index unic – Pentru tabelele cu un index unic, aveți posibilitatea de a utiliza indexul pentru comandă identifică datele duplicate, apoi eliminați registrele duplicate. Identificarea poate fi realizată cu auto-îmbinări, ordonând datele după valoarea maximă, utilizând funcția RANK sau folosind logica NOT IN.
- Tabel fără un index unic – Pentru tabelele fără un index unic, este un pic mai mult provocator. În acest scenariu, funcția ROW_NUMBER () poate fi utilizată cu o expresie de tabelă comună (CTE) pentru a sorta datele, apoi pentru a șterge înregistrările duplicate ulterioare.
Consultați exemplele de mai jos pentru a obține exemple din lumea reală despre cum să ștergeți duplicateecords dintr-un tabel.
Eliminarea rândurilor duplicate dintr-un tabel SQL Server cu un index unic
Configurarea mediului de testare
Pentru a ne îndeplini sarcinile, avem nevoie de un mediu de testare:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Acum, să introducem date în „TableA”:
După cum putem vedea, valorile 3 și 5 există în coloana „Valoare” de mai multe ori:
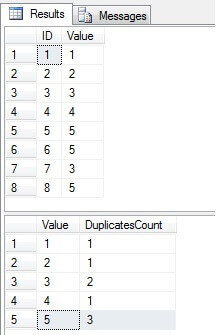
Identificați rândurile duplicate în a SQL Server Table
Sarcina noastră este de a impune unicitatea pentru coloana „Valoare” prin eliminarea duplicatelor. Eliminarea valorilor duplicate din tabel cu un index unic este puțin mai ușoară decât eliminarea rândurilor dintr-un tabel fără acesta. Mai întâi dintre toate, trebuie să găsim duplicate. Există multe modalități diferite de a face acest lucru. Să „s investigați și comparați câteva moduri comune. În codul de mai jos există șase soluții pentru a găsi acele valori duplicat care ar trebui șterse (lăsând o singură valoare):
După cum putem vedea, rezultatul pentru toate cazurile este același:
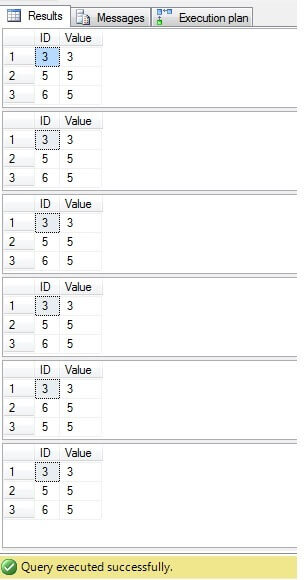
Doar rândurile cu ID = 3, 5, 6 trebuie șterse. Privind planul de execuție putem vedea că cel mai recent – cea mai „compactă” soluție („Soluția 6”) are un cost mai ridicat (în exemplul nostru există o cheie principală în coloana „ID”, deci valorile „NULL” nu sunt posibile pentru acea coloană, prin urmare, „NOT IN” va funcționa fără nicio problemă), iar a doua are cel mai mic cost:

Ștergerea Duplicați rândurile într-un tabel SQL Server
Acum, folosind aceste interogări, să ștergem valorile duplicate din tabel. Pentru a simplifica procesul nostru, vom folosi doar a doua, a cincea și a șasea interogare:
Ștergând datele și analizând planurile de execuție din nou, vedem că cea mai rapidă este prima comandă ȘTERGERE și cea mai lentă este ultima așa cum era de așteptat:
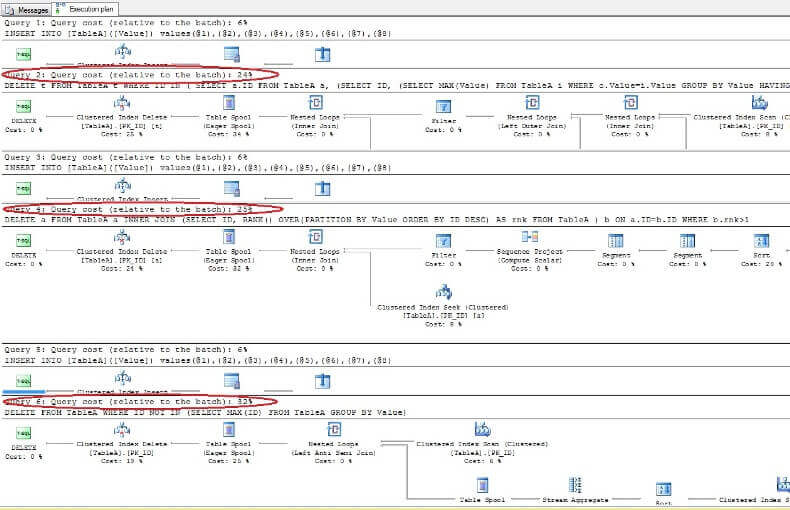
Eliminarea duplicatelor din tabel fără un index unic în ORACLE
Ca mijloc de a ilustra exemplul nostru final din acest sfat, vreau să explic câteva funcționalități similare în Oracle. Eliminarea duplicatului rânduri de la t capabil fără un index unic este puțin mai ușor în Oracle decât în SQL Server. Există o pseudo coloană ROWID în Oracle care returnează adresa rândului. Identifică în mod unic rândul din tabel (de obicei și în baza de date, dar în acest caz, există o excepție – dacă tabele diferite stochează date în același cluster pot avea același ROWID).Interogarea de mai jos creează și inserează date în tabel în baza de date Oracle:
Acum selectăm datele și ROWID din tabel:
SELECT ROWID, Value FROM TableB;
Rezultatul este mai jos:
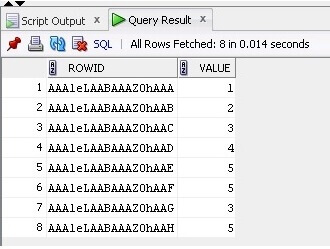
Acum folosind ROWID, vom elimina cu ușurință rândurile duplicate din tabel:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
De asemenea, putem elimina duplicatele folosind codul de mai jos:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Eliminarea duplicatelor dintr-un tabel SQL Server fără un index unic
Spre deosebire de Oracle, nu există ROWID în SQL Server, deci pentru a elimina duplicatele din tabel fără un index unic pe care trebuie să-l facem pentru a crea lucruri suplimentare pentru generarea de identificatori uniquerow:
În codul de mai sus, creăm un tabel cu rânduri duplicate. Generăm identificatori unici folosind funcția ROW_NUMBER () și folosind expresia de masă comună (CTE) ștergem duplicatele:
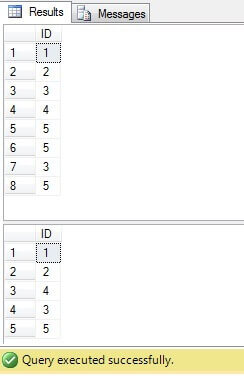
Totuși, acest cod poate fi înlocuit cu unul mai compact și optim:
Acestea fiind spuse, este posibil să se identifice și adresa fizică a rândului SQL Server. În ciuda faptului că este practic imposibil să găsiți documentație oficială despre această caracteristică, aceasta poate fi utilizată ca analog cu coloana ROWIDpseudo din Oracle. Se numește %% physloc %% (din SQL Server 2008) și este o coloană binară virtuală (8) care arată locația fizică a rândului. Deoarece valoarea %% physloc %% este unică pentru fiecare rând, îl putem folosi ca un identificator de rând în timp ce ștergeți rândurile duplicate dintr-un tabel fără un index unic. Astfel, putem elimina rânduri duplicate dintr-un tabel fără un index unic în SQL Server, ca în Oracleas, precum și în cazul în care tabelul are un index unic.
Primele două interogări de mai jos sunt versiunile echivalente de eliminare a duplicatelor în Oracle, următoarele două sunt interogări pentru eliminarea duplicatelor folosind %% physloc %% similarto în cazul tabelului cu un index unic, iar în ultima interogare, %% physloc %% nu este utilizat doar pentru a compara performanța tuturor acestor opțiuni:
Analizând planurile de execuție, putem vedea că prima și ultima interogare sunt cele mai rapide în comparație cu lotul general times:
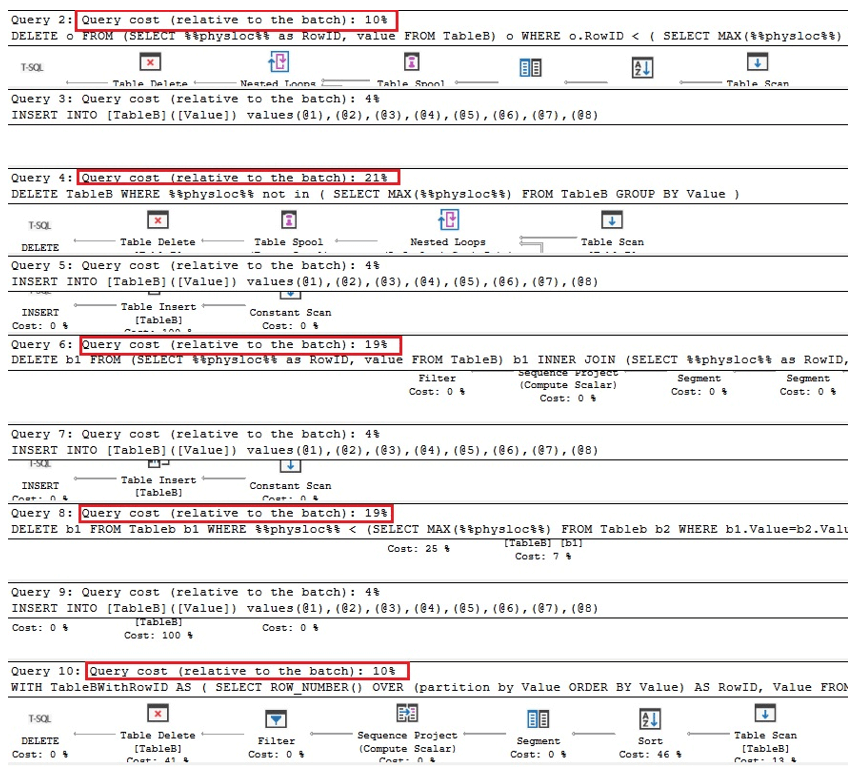
Prin urmare, putem concluziona că, în general, utilizarea %% physloc %% nu îmbunătățește performanța. În timp ce utilizați această abordare, este foarte important să vă dați seama că aceasta este o caracteristică nedocumentată a SQL Server și, prin urmare, dezvoltatorii ar trebui să fie foarte atenți.
Există alte modalități de a elimina duplicatele care nu sunt discutate în acest sfat. De exemplu, putem stoca rânduri distincte într-un tabel temporar, apoi ștergem toate datele din tabelul nostru și apoi inserăm rânduri distincte din tabelul temporar în tabelul nostru permanent. În acest caz, instrucțiunile DELETE și INSERT ar trebui incluse într-o singură tranzacție.
Concluzie
În timpul experienței noastre ne confruntăm cu situații în care trebuie să curățăm valorile duplicate din tabelele SQL Server. Valorile duplicate pot fi în coloana care va fi duplicată în funcție de cerințele noastre sau tabelul poate conține rânduri duplicate. În ambele cazuri, trebuie să excludem datele pentru a evita duplicarea datelor în baza de date. În acest sfat am explicat câteva tehnici care, sperăm, vor fi utile pentru rezolvarea acestor tipuri de probleme.
Pașii următori
Ultima actualizare: 16.08.2019


Despre autor
 Sergey Gigoyan este un profesionist în baze de date cu peste 10 ani de experiență, cu accent pe proiectarea bazelor de date, dezvoltarea, reglarea performanțelor, optimizarea, disponibilitatea ridicată, BI și proiectarea DW. sfaturi
Sergey Gigoyan este un profesionist în baze de date cu peste 10 ani de experiență, cu accent pe proiectarea bazelor de date, dezvoltarea, reglarea performanțelor, optimizarea, disponibilitatea ridicată, BI și proiectarea DW. sfaturi - Mai multe sfaturi pentru dezvoltatori de baze de date …