Encontre e remova linhas duplicadas de uma tabela do SQL Server
Por: Sergey Gigoyan | Atualizado: 16/08/2019 | Comentários (11) | Relacionado: Mais > Design do banco de dados
Problema
De acordo com as práticas recomendadas do todatabasedesign, uma tabela do SQL Server não deve conter linhas duplicadas. Durante o processo de design do banco de dados, as chaves primárias devem ser criadas para eliminar linhas duplicadas. No entanto, às vezes precisamos trabalhar com bancos de dados onde essas regras não são seguidas ou onde exceções são possíveis (quando essas regras são contornadas conscientemente). Por exemplo, quando uma tabela de teste é usada e os dados são carregados de fontes diferentes onde linhas duplicadas são possíveis. Quando o processo de carregamento é concluído, a tabela deve ser limpa ou os dados limpos devem ser carregados em uma tabela permanente, para que depois disso não sejam mais necessárias duplicatas. Portanto, surge um problema relacionado à remoção de duplicatas da mesa de carregamento. Nesta dica, vamos examinar algumas maneiras de resolver as necessidades de eliminação da duplicação de dados.
Solução
Vamos considerar dois casos nesta dica:
- O primeiro caso é quando uma tabela do SQL Server tem uma chave primária (ou índice exclusivo) e uma das colunas contém valores duplicados que devem ser removidos.
- O segundo caso é que a tabela não tem uma chave primária ou qualquer índice único e contém linhas duplicadas que devem ser removidas. Vamos discutir esses casos separadamente.
Como remover linhas duplicadas em uma tabela do SQL Server
Registros duplicados em uma tabela do SQL Server pode ser um problema muito sério. Com dados duplicados, é possível que os pedidos sejam processados inúmeras vezes, tenham resultados imprecisos para relatórios e muito mais. No SQL Server, há várias maneiras de lidar com registros duplicados em uma tabela com base em circunstâncias específicas, como:
- Tabela com índice exclusivo – para tabelas com índice exclusivo, você tem a oportunidade de usar o índice para identificar os dados duplicados e, em seguida, remover os registros duplicados. A identificação pode ser realizada com autojunções, ordenando os dados pelo valor máximo, usando a função RANK ou usando a lógica NOT IN.
- Tabela sem um índice exclusivo – Para tabelas sem um índice exclusivo, é um pouco mais desafiador. Nesse cenário, a função ROW_NUMBER () pode ser usada com uma expressão de tabela comum (CTE) para classificar os dados e excluir os registros duplicados subsequentes.
Verifique os exemplos abaixo para obter exemplos do mundo real sobre como excluir registros duplicados de uma tabela.
Remoção de linhas duplicadas de uma tabela do SQL Server com um índice exclusivo
Configuração do ambiente de teste
Para realizar nossas tarefas, precisamos de um ambiente de teste:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Agora, vamos inserir os dados na “TabelaA”:
Como podemos ver, os valores 3 e 5 existem na coluna “Valor” mais de uma vez:
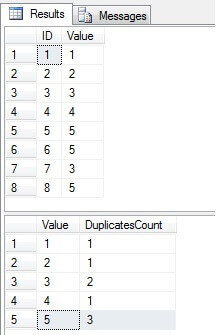
Identifique linhas duplicadas em uma tabela do SQL Server
Nossa tarefa é impor exclusividade para a coluna “Valor” removendo duplicatas. Remover valores duplicados de uma tabela com um índice exclusivo é um pouco mais fácil do que remover as linhas de uma tabela sem ele. de tudo, precisamos encontrar duplicatas. Existem muitas maneiras diferentes de fazer isso. investigue e compare algumas maneiras comuns. No código abaixo, existem seis soluções para encontrar os valores duplicados que devem ser excluídos (deixando apenas um valor):
Como podemos ver, o resultado para todos os casos é o mesmo:
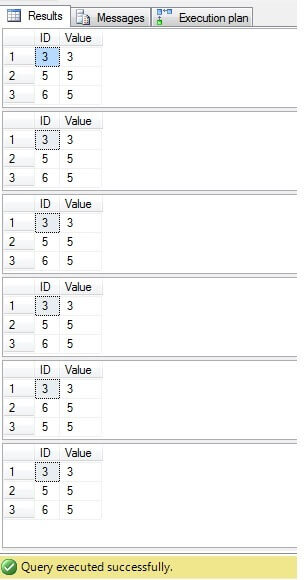
Apenas as linhas com ID = 3, 5, 6 precisam ser excluídas. Olhando para o plano de execução, podemos ver que mais recente – a solução mais “compacta” (“Solução 6”) tem um custo mais alto (em nosso exemplo, há uma chave primária na coluna “ID”, portanto valores “NULL” não são possíveis para essa coluna, portanto “NOT IN” funcionará sem problemas), e a segunda tem o custo mais baixo:

Excluindo Linhas duplicadas em uma tabela do SQL Server
Agora, usando essas consultas, vamos excluir valores duplicados da tabela. Para simplificar nosso processo, usaremos apenas a segunda, a quinta e a sexta consultas:
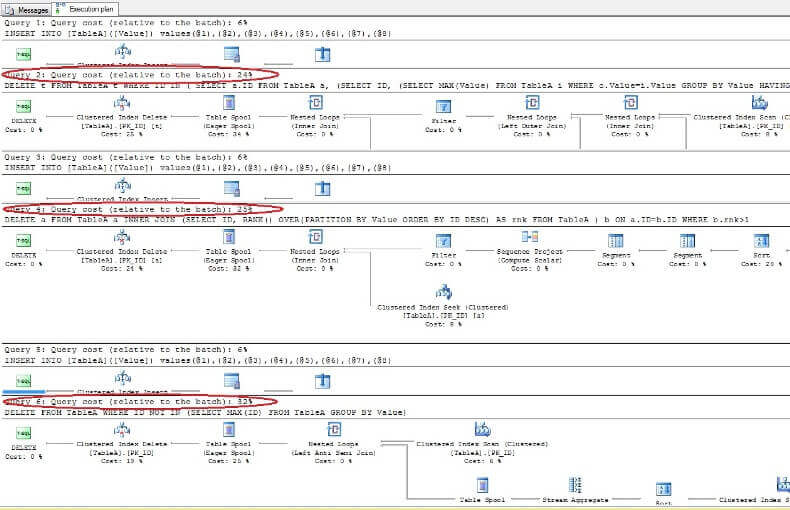
Excluindo os dados e examinando os planos de execução novamente, vemos que o mais rápido é o primeiro comando DELETE e o mais lento é o último conforme o esperado:
Removendo duplicatas da tabela sem um índice exclusivo no ORACLE
Como uma forma de ajudar a ilustrar nosso exemplo final nesta dica, eu quero explicar algumas funcionalidades semelhantes no Oracle. Removendo duplicatas linhas do t capaz sem um índice exclusivo é um pouco mais fácil no Oracle do que no SQL Server. Existe uma pseudocoluna ROWID no Oracle que retorna o endereço da linha. Ele identifica exclusivamente a linha na tabela (geralmente no banco de dados também, mas, neste caso, há uma exceção – se diferentes tabelas armazenam dados no mesmo cluster, podem ter o mesmo ROWID).A consulta abaixo cria e insere dados na tabela do banco de dados Oracle:
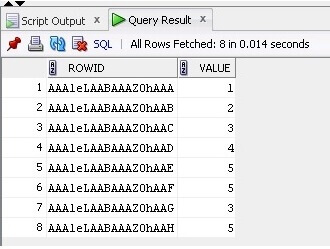
Agora estamos selecionando os dados e o ROWID da tabela:
SELECT ROWID, Value FROM TableB;
O resultado está abaixo:
Agora usando o ROWID, removeremos facilmente as linhas duplicadas de tabela:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Também podemos remover duplicatas usando o código abaixo:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Removendo duplicatas de uma tabela do SQL Server sem um índice exclusivo
Ao contrário do Oracle, não há ROWID no SQL Server, para remover duplicatas da tabela sem um índice único, precisamos fazer um trabalho adicional para gerar identificadores uniquerow:
No código acima, estamos criando uma tabela com linhas duplicadas. Estamos gerando identificadores únicos usando a função ROW_NUMBER () e usando a expressão de tabela comum (CTE) estamos excluindo duplicatas:
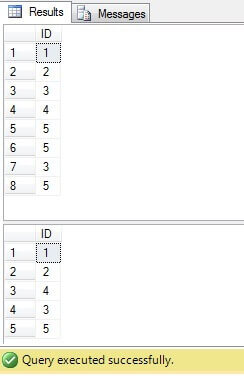
Este código, entretanto, pode ser substituído por um mais compacto e ideal:
Posto isso, é possível identificar o endereço físico do rowin SQL Server também. Apesar de ser praticamente impossível encontrar documentação oficial sobre este recurso, ele pode ser usado como um análogo à pseudo coluna ROWID no Oracle. É chamado de %% physloc %% (desde SQL Server 2008) e é uma coluna binária virtual (8) que mostra a localização física da linha. Como o valor de %% physloc %% é único para cada linha, podemos usá-lo como um identificador de linha ao remover linhas duplicadas de uma tabela sem um índice exclusivo. Portanto, podemos remover linhas duplicadas de uma tabela sem um índice exclusivo no SQL Server, como no Oracleas, bem como no caso em que a tabela tem um índice exclusivo.
As duas primeiras consultas abaixo são as versões equivalentes de remoção de duplicatas no Oracle, as próximas duas são consultas para remoção de duplicatas usando %% physloc %% semelhante ao caso da tabela com um índice único, e no último query, %% physloc %% não é usado apenas para comparar o desempenho de todas essas opções:
Analisando os planos de execução, podemos ver que a primeira e a última consultas são as mais rápidas quando comparadas ao lote geral vezes:
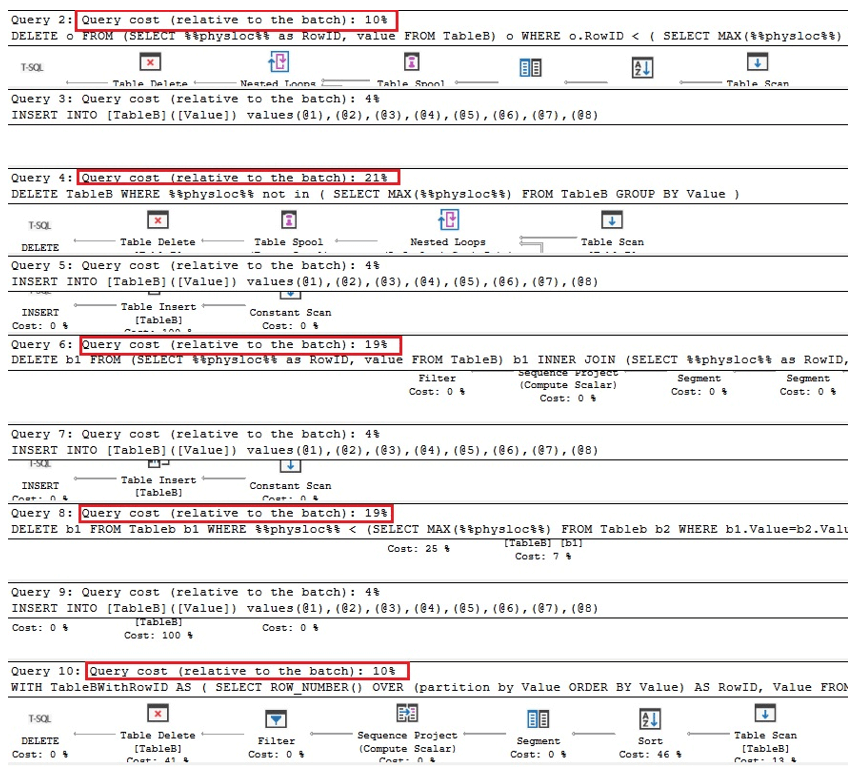
Portanto, podemos concluir que em geral, usar %% physloc %% não melhora o desempenho. Ao usar essa abordagem, é muito importante perceber que esse é um recurso não documentado do SQL Server e, portanto, os desenvolvedores devem ser muito cuidadosos.
Existem outras maneiras de remover duplicatas que não são discutidas nesta dica. Por exemplo, podemos armazenar linhas distintas em uma tabela temporária, excluir todos os dados de nossa tabela e depois inserir linhas distintas da tabela temporária em nossa tabela permanente. Nesse caso, as instruções DELETE e INSERT devem ser incluídas em uma transação.
Conclusão
Durante nossa experiência, enfrentamos situações em que precisamos limpar valores duplicados das tabelas do SQL Server. Os valores duplicados podem estar na coluna que será duplicada com base em nossos requisitos ou a tabela pode conter linhas duplicadas. Em ambos os casos, precisamos excluir os dados para evitar a duplicação de dados no banco de dados. Nesta dica, explicamos algumas técnicas que, esperançosamente, serão úteis para resolver esses tipos de problemas.
Próximas etapas
Última atualização: 16/08/2019


Sobre o autor
 Sergey Gigoyan é um profissional de banco de dados com mais de 10 anos de experiência, com foco em design de banco de dados, desenvolvimento, ajuste de desempenho, otimização, alta disponibilidade, design de BI e DW.
Sergey Gigoyan é um profissional de banco de dados com mais de 10 anos de experiência, com foco em design de banco de dados, desenvolvimento, ajuste de desempenho, otimização, alta disponibilidade, design de BI e DW. Ver todos meus dicas
- Mais dicas para desenvolvedores de banco de dados …