Znajdź i usuń zduplikowane wiersze z tabeli programu SQL Server
Autor: Sergey Gigoyan | Zaktualizowano: 2019-08-16 | Komentarze (11) | Powiązane: Więcej > Projekt bazy danych
Problem
Zgodnie z najlepszymi praktykami todatabasedesign tabela programu SQL Server nie powinna zawierać zduplikowanych wierszy. Podczas projektowania bazy danych należy utworzyć klucze podstawowe, aby wyeliminować zduplikowane wiersze. Czasami jednak musimy pracować z bazami danych, w których te reguły nie są przestrzegane lub możliwe są wyjątki (gdy te reguły są omijane świadomie). Na przykład, gdy używana jest tabela pomostowa i dane są ładowane z różnych źródeł, w których możliwe są zduplikowane wiersze. Po zakończeniu procesu ładowania tabelę należy wyczyścić lub wyczyścić dane należy załadować do tabeli trwałej, aby po tym czasie duplikaty nie były już potrzebne. W związku z tym pojawia się kwestia usuwania duplikatów z tabeli załadunkowej. W tej wskazówce przyjrzyjmy się kilku sposobom rozwiązania problemów związanych z deduplikacją danych.
Rozwiązanie
W tej wskazówce rozważymy dwa przypadki:
- Pierwszy przypadek ma miejsce, gdy tabela SQL Server ma klucz podstawowy (lub unikalny indeks), a jedna z kolumn zawiera zduplikowane wartości, które należy usunąć.
- Drugi przypadek jest taki, że tabela nie ma klucza podstawowego lub jakiekolwiek unikalne indeksy i zawiera zduplikowane wiersze, które powinny zostać usunięte. Omówmy te przypadki osobno.
Jak usunąć zduplikowane wiersze w tabeli SQL Server
Zduplikowane rekordy w tabela SQL Server może być bardzo poważnym problemem. Dzięki zduplikowanym danym możliwe jest wielokrotne przetwarzanie zamówień, niedokładne wyniki raportowania i nie tylko. W SQL Server istnieje wiele sposobów na adresowanie zduplikowanych rekordów w tabeli w zależności od określonych okoliczności, takich jak:
- Tabela z unikalnym indeksem – W przypadku tabel z unikalnym indeksem masz możliwość użycia indeks w celu zidentyfikowania zduplikowanych danych, a następnie usuń duplikaty rekordów. Identyfikację można przeprowadzić za pomocą samospłączeń, uporządkowania danych według wartości maksymalnej, za pomocą funkcji RANK lub za pomocą logiki NOT IN.
- Tabela bez unikalnego indeksu – W przypadku tabel bez unikalnego indeksu jest to nieco więcej trudne. W tym scenariuszu funkcja ROW_NUMBER () może być używana ze wspólnym wyrażeniem tabelowym (CTE) do sortowania danych, a następnie usuwania kolejnych zduplikowanych rekordów.
Zapoznaj się z poniższymi przykładami, aby uzyskać rzeczywiste przykłady o tym, jak usunąć duplicaterecords z tabeli.
Usuwanie zduplikowanych wierszy z tabeli SQL Server z unikalnym indeksem
Konfiguracja środowiska testowego
Aby wykonać nasze zadania, potrzebujemy środowiska testowego:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Teraz wstawmy dane do „TableA”:
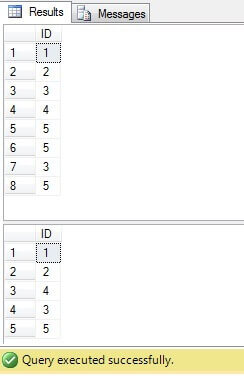
Jak widzimy, wartości 3 i 5 istnieją w kolumnie „Wartość” więcej niż raz:
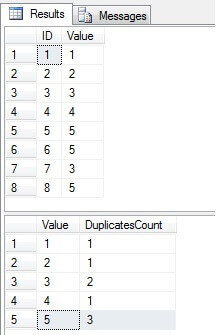
Zidentyfikuj zduplikowane wiersze w a SQL Server Table
Naszym zadaniem jest wymuszenie unikalności kolumny „Value” poprzez usunięcie duplikatów. Usunięcie zduplikowanych wartości z tabeli z unikalnym indeksem jest nieco łatwiejsze niż usunięcie wierszy z tabeli bez niego. Po pierwsze przede wszystkim musimy znaleźć duplikaty. Jest na to wiele różnych sposobów zbadaj i porównaj kilka typowych sposobów.W poniższym kodzie znajduje się sześć rozwiązań pozwalających znaleźć zduplikowane wartości, które powinny zostać usunięte (pozostawiając tylko jedną wartość):
Jak widzimy, wynik dla wszystkich przypadków jest taki sam:
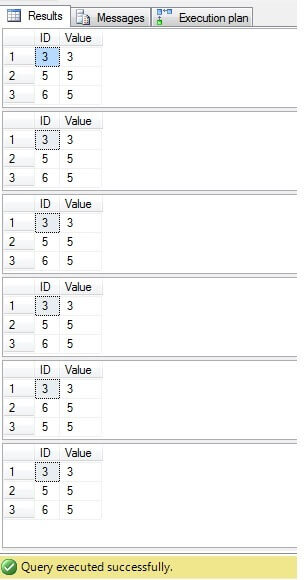
Należy usunąć tylko wiersze o identyfikatorze = 3, 5, 6. Patrząc na plan wykonania, możemy zobaczyć, że najnowsze – najbardziej „kompaktowe” rozwiązanie („Rozwiązanie 6”) ma najwyższy koszt (w naszym przykładzie klucz główny znajduje się w kolumnie „ID”, więc wartości „NULL” nie są możliwe dla ta kolumna, dlatego „NOT IN” będzie działać bez problemu), a druga ma najniższy koszt:

Usuwanie Zduplikowane wiersze w tabeli SQL Server
Teraz używając tych zapytań, usuńmy zduplikowane wartości z tabeli. Aby uprościć nasz proces, użyjemy tylko drugiego, piątego i szóstego zapytania:
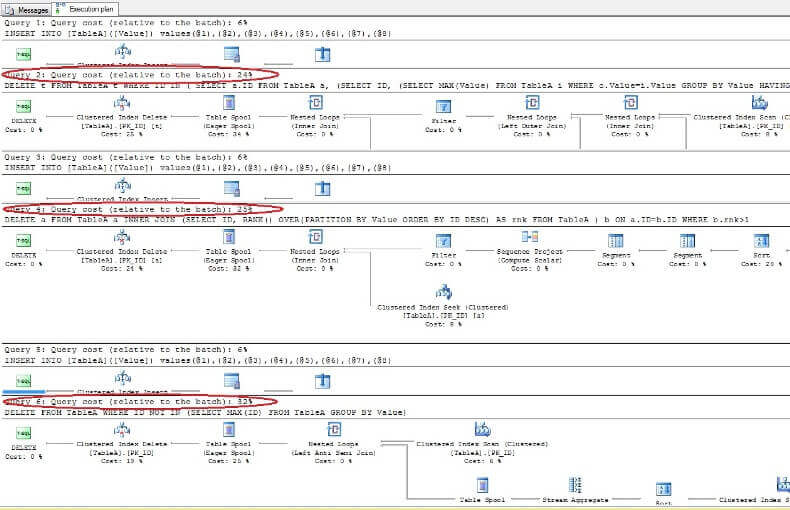
Po usunięciu danych i ponownym przejrzeniu planów wykonania widzimy, że najszybsze to pierwsze polecenie DELETE, a najwolniejsze jest ostatnie zgodnie z oczekiwaniami:
Usuwanie duplikatów z tabeli bez unikalnego indeksu w ORACLE
Aby pomóc zilustrować nasz ostatni przykład w tej wskazówce, chcę wyjaśnić niektóre podobne funkcje w Oracle. Usuwanie duplikatów rzędy od t ablbez unikatowego indeksu jest trochę łatwiejszy w Oracle niż w SQL Server. W Oracle istnieje pseudokolumna ROWID, która zwraca adres wiersza. W sposób jednoznaczny identyfikuje wiersz w tabeli (zwykle również w bazie danych, ale w tym przypadku jest wyjątek – jeśli różne tabele przechowują dane w tym samym klastrze, mogą mieć ten sam ROWID).Poniższe zapytanie tworzy i wstawia dane do tabeli w bazie danych Oracle:
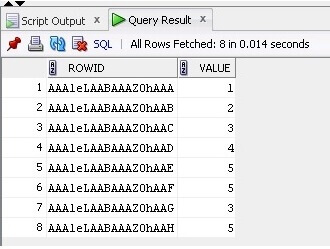
Teraz wybieramy dane i ROWID z tabeli:
SELECT ROWID, Value FROM TableB;
Wynik jest poniżej:
Teraz używając ROWID, z łatwością usuniemy zduplikowane wiersze z table:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Możemy również usunąć duplikaty za pomocą poniższego kodu:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Usuwanie duplikatów z tabeli SQL Server bez unikalnego indeksu
W przeciwieństwie do Oracle, w SQL Server nie ma ROWID, więc aby usunąć duplikaty z tabeli bez unikalny indeks, musimy wykonać dodatkową pracę, aby wygenerować unikalne identyfikatory:
W powyższym kodzie tworzymy tabelę ze zduplikowanymi wierszami. Generujemy unikalne identyfikatory za pomocą funkcji ROW_NUMBER () i używając wspólnego wyrażenia tabelowego (CTE) usuwamy duplikaty:
Ten kod można jednak zastąpić bardziej zwartym i optymalnym:
Powiedziawszy to, możliwe jest również zidentyfikowanie fizycznego adresu wiersza w SQL Server. Pomimo tego, że znalezienie oficjalnej dokumentacji na temat tej funkcji jest praktycznie niemożliwe, można ją wykorzystać jako analog do pseudokolumny ROWID w Oracle. Nazywa się %% physloc %% (od SQL Server 2008) i jest wirtualną kolumną binarną (8), która pokazuje fizyczną lokalizację wiersza. Ponieważ wartość %% physloc %% jest unikalna dla każdego wiersza, możemy użyć jej jako identyfikatora wiersza podczas usuwania zduplikowanych wierszy z tabeli bez unikalnego indeksu. W ten sposób możemy usunąć zduplikowane wiersze z tabeli bez unikalnego indeksu w SQL Server, tak jak w Oracle, jak również w przypadku, gdy tabela ma unikalny indeks.
Pierwsze dwa zapytania poniżej to równoważne wersje usuwania duplikatów w Oracle, następne dwa to zapytania do usuwania duplikatów przy użyciu %% physloc %%, podobnie jak wielkość liter w tabeli z unikalnym indeksem, a w ostatnim zapytanie, %% physloc %% nie jest używane tylko do porównywania wydajności wszystkich tych opcji:
Analizując plany wykonania, widzimy, że pierwsze i ostatnie zapytanie są najszybsze w porównaniu do całej partii razy:
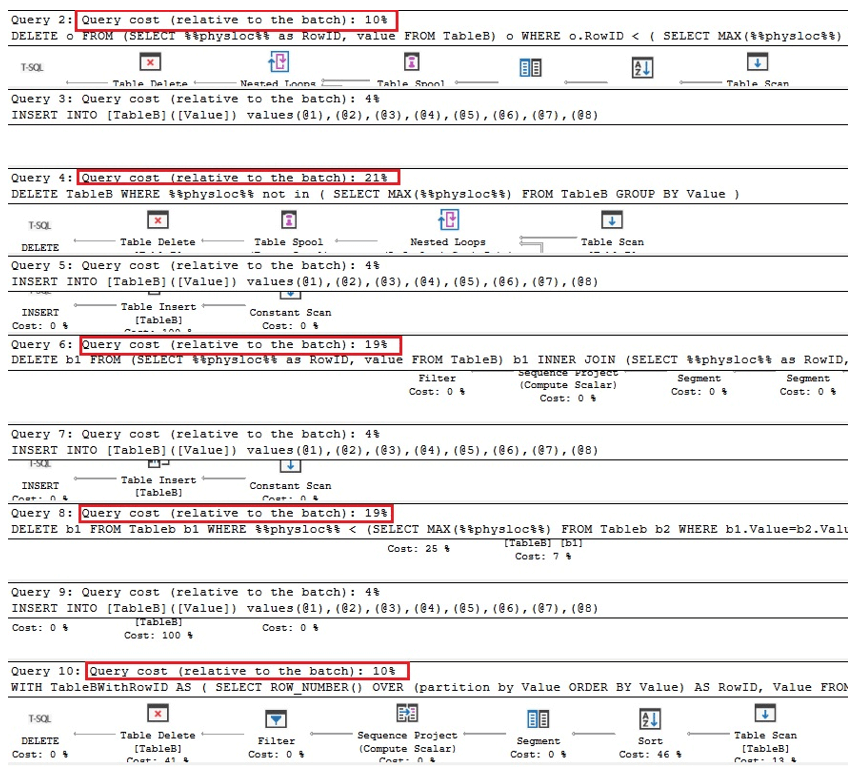
Stąd możemy wywnioskować, że generalnie użycie %% physloc %% nie poprawia wydajności. Korzystając z tego podejścia, bardzo ważne jest, aby zdać sobie sprawę, że jest to nieudokumentowana funkcja SQL Server i dlatego programiści powinni być bardzo ostrożni.
Istnieją inne sposoby usuwania duplikatów, które nie są omówione w tej wskazówce. Na przykład, możemy przechowywać różne wiersze w tabeli tymczasowej, a następnie usunąć wszystkie dane z naszej tabeli, a następnie wstawić odrębne wiersze z tabeli tymczasowej do naszej tabeli stałej. W takim przypadku instrukcje DELETE i INSERT powinny być zawarte w jednej transakcji.
Wniosek
Z doświadczenia wiemy, że musimy wyczyścić zduplikowane wartości z tabel SQL Server. Zduplikowane wartości mogą znajdować się w kolumnie, która zostanie zduplikowana zgodnie z naszymi wymaganiami lub tabela może zawierać zduplikowane wiersze. W obu przypadkach musimy wykluczyć dane, aby uniknąć powielania danych w bazie danych. W tej wskazówce wyjaśniliśmy niektóre techniki, które, miejmy nadzieję, będą pomocne przy rozwiązywaniu tego typu problemów.
Następne kroki
Ostatnia aktualizacja: 16.08.2019


O autorze
 Sergey Gigoyan jest specjalistą od baz danych z ponad 10-letnim doświadczeniem, specjalizującym się w projektowaniu baz danych, rozwoju, dostrajaniu wydajności, optymalizacji, wysokiej dostępności, projektowaniu BI i DW. porady
Sergey Gigoyan jest specjalistą od baz danych z ponad 10-letnim doświadczeniem, specjalizującym się w projektowaniu baz danych, rozwoju, dostrajaniu wydajności, optymalizacji, wysokiej dostępności, projektowaniu BI i DW. porady - Więcej wskazówek dla programistów baz danych …