Zoek en verwijder dubbele rijen uit een SQL Server-tabel
Door: Sergey Gigoyan | Bijgewerkt: 2019-08-16 | Reacties (11) | Gerelateerd: Meer > Databaseontwerp
Probleem
Volgens de best practices van todatabasedesign mag een SQL Server-tabel geen dubbele rijen bevatten. Tijdens het ontwerpproces van de database moeten primaire sleutels worden gemaakt om dubbele rijen te elimineren. Soms moeten we echter werken met databases waarin deze regels niet worden gevolgd of waar uitzonderingen mogelijk zijn (wanneer deze regels bewust worden omzeild). Wanneer bijvoorbeeld een verzameltabel wordt gebruikt en gegevens worden geladen uit verschillende bronnen waar dubbele rijen mogelijk zijn. Wanneer het laadproces is voltooid, moet de tabel worden opgeschoond of moeten schone gegevens worden geladen in een permanente tabel, zodat daarna geen duplicaten meer nodig zijn. Daarom doet zich een probleem voor met betrekking tot het verwijderen van duplicaten van de laadtafel. Laten we in deze tip eens kijken naar enkele manieren om het ontdubbelen van gegevens op te lossen.
Oplossing
We zullen in deze tip twee gevallen beschouwen:
- Het eerste geval is wanneer een SQL Server-tabel een primaire sleutel (of unieke index) heeft en een van de kolommen dubbele waarden bevat die moeten worden verwijderd.
- Het tweede geval is dat de tabel geen primaire sleutel heeft of enige unieke indexen en bevat dubbele rijen die moeten worden verwijderd. Laten we deze gevallen afzonderlijk bespreken.
Hoe verwijder je dubbele rijen in een SQL Server-tabel
Dubbele records in een SQL Server-tabel kan een zeer ernstig probleem zijn. Met dubbele gegevens is het mogelijk dat bestellingen meerdere keren worden verwerkt, onnauwkeurige resultaten hebben voor rapportage en meer. In SQL Server zijn er een aantal manieren om dubbele records in een tabel aan te pakken op basis van de specifieke omstandigheden, zoals:
- Tabel met unieke index – voor tabellen met een unieke index heeft u de mogelijkheid om de index om de dubbele gegevens te bestellen en vervolgens de dubbele gegevens te verwijderen. Identificatie kan worden uitgevoerd met self-joins, waarbij de gegevens worden gerangschikt op de maximale waarde, de RANK-functie wordt gebruikt of de NOT IN-logica wordt gebruikt.
- Tabel zonder een unieke index – Voor tabellen zonder een unieke index is het een beetje meer uitdagend. In dit scenario kan de functie ROW_NUMBER () worden gebruikt met een gemeenschappelijke tabelexpressie (CTE) om de gegevens te sorteren en vervolgens de daaropvolgende dubbele records te verwijderen.
Bekijk de onderstaande voorbeelden voor voorbeelden uit de echte wereld over het verwijderen van dubbele records uit een tabel.
Verwijderen van dubbele rijen uit een SQL Server-tabel met een unieke index
Testomgeving instellen
Om onze taken uit te voeren, we hebben een testomgeving nodig:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Laten we nu gegevens invoegen in “TableA”:
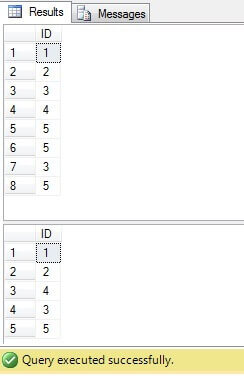
Zoals we kunnen zien, bestaan de waarden 3 en 5 meer dan eens in de kolom “Waarde”:
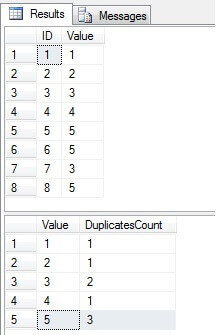
Identificeer dubbele rijen in a SQL Server Table
Het is onze taak om de uniciteit van de “Value” -kolom af te dwingen door duplicaten te verwijderen. Het verwijderen van dubbele waarden uit een tabel met een unieke index is een beetje eenvoudiger dan het verwijderen van de rijen uit een tabel zonder. van alles moeten we duplicaten vinden. Er zijn veel verschillende manieren om dat te doen. Laten we onderzoek en vergelijk enkele veelvoorkomende manieren. In de onderstaande code zijn er zes oplossingen om dubbele waarden te vinden die moeten worden verwijderd (laat slechts één waarde over):
Zoals we kunnen zien is het resultaat voor alle gevallen hetzelfde:
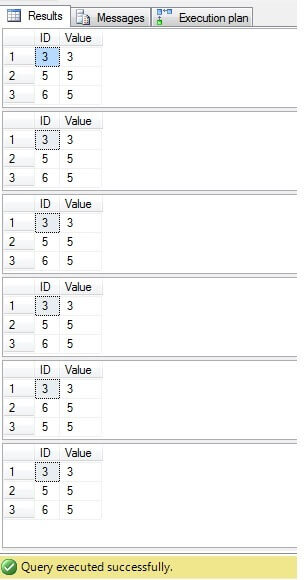
Alleen rijen met ID = 3, 5, 6 moeten worden verwijderd. Als we naar het uitvoeringsplan kijken, kunnen we zien dat de laatste – de meest compacte oplossing (Oplossing 6) de hoogste kosten met zich meebrengt (in ons voorbeeld staat er een primaire sleutel in de kolom ID, dus NULL-waarden zijn niet mogelijk voor die kolom, dus “NOT IN” zal zonder enig probleem werken), en de tweede heeft de laagste kosten:

Verwijderen Dubbele rijen in een SQL Server-tabel
Laten we nu met behulp van deze querys dubbele waarden uit de tabel verwijderen. Om ons proces te vereenvoudigen, zullen we alleen de tweede, de vijfde en de zesde query gebruiken:
Door de gegevens te verwijderen en de uitvoeringsplannen opnieuw te bekijken, zien we dat de snelste de eerste DELETE-opdracht is en de langzaamste de laatste zoals verwacht:
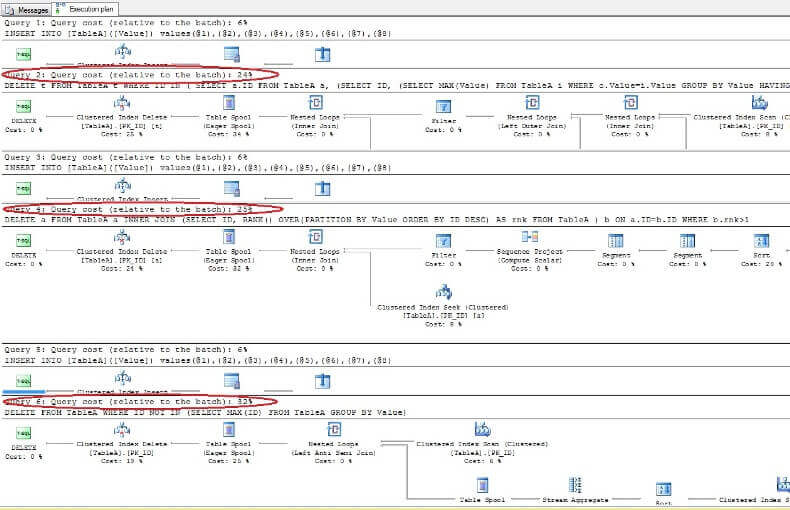
Duplicaten uit de tabel verwijderen zonder een unieke index in ORACLE
Als een middel om ons laatste voorbeeld in deze tip te helpen illustreren, wil ik een aantal vergelijkbare functionaliteit in Oracle uitleggen. rijen van de t zonder een unieke index is in Oracle iets eenvoudiger dan in SQL Server. Er is een ROWID pseudokolom in Oracle die het adres van de rij retourneert. Het identificeert op unieke wijze de rij in de tabel (meestal ook in de database, maar in dit geval is er een uitzondering: als verschillende tabellen gegevens opslaan in hetzelfde cluster, kunnen ze dezelfde ROWID hebben).De onderstaande query creëert en voegt gegevens in de tabel in de Oracle-database in:
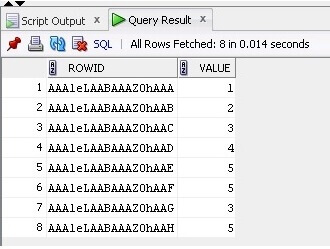
Nu selecteren we de gegevens en ROWID uit de tabel:
SELECT ROWID, Value FROM TableB;
Het resultaat is hieronder:
Nu we ROWID gebruiken, zullen we gemakkelijk dubbele rijen verwijderen uit table:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
We kunnen ook duplicaten verwijderen met de onderstaande code:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Duplicaten verwijderen uit een SQL Server-tabel zonder een unieke index
In tegenstelling tot Oracle is er geen ROWID in SQL Server, dus om duplicaten uit de tabel te verwijderen zonder een unieke index die we nodig hebben om extra werk te doen voor het genereren van unieke rij-IDs:
In de bovenstaande code maken we een tabel met dubbele rijen. We genereren unieke IDs met behulp van de functie ROW_NUMBER () en met behulp van de gewone tabelexpressie (CTE) verwijderen we duplicaten:
Deze code kan echter worden vervangen door een meer compacte en optimale:
Dat gezegd hebbende, is het ook mogelijk om het fysieke adres van de rowin SQL Server te identificeren. Ondanks het feit dat het praktisch onmogelijk is om officiële documentatie over deze functie te vinden, kan het worden gebruikt als een analoog aan de ROWIDpseudo-kolom in Oracle. Het heet %% physloc %% (sinds SQL Server 2008) en het is een virtuele binaire (8) kolom die de fysieke locatie van de rij toont. Omdat de waarde van %% physloc %% uniek is voor elke rij, kunnen we deze gebruiken als een rij-ID terwijl dubbele rijen uit een tabel worden verwijderd zonder een unieke index. We kunnen dus dubbele rijen uit een tabel verwijderen zonder een unieke index in SQL Server, zoals in Oracleas, evenals in het geval dat de tabel een unieke index heeft.
De eerste twee vragen hieronder zijn de equivalente versies van het verwijderen van duplicaten in Oracle, de volgende twee zijn zoekopdrachten voor het verwijderen van duplicaten met %% physloc %% vergelijkbaar met het geval van de tabel met een unieke index, en in de laatste query, %% physloc %% wordt niet alleen gebruikt om de prestaties van al deze opties te vergelijken:
Bij het analyseren van de uitvoeringsplannen kunnen we zien dat de eerste en de laatste query het snelst zijn in vergelijking met de totale batch keer:
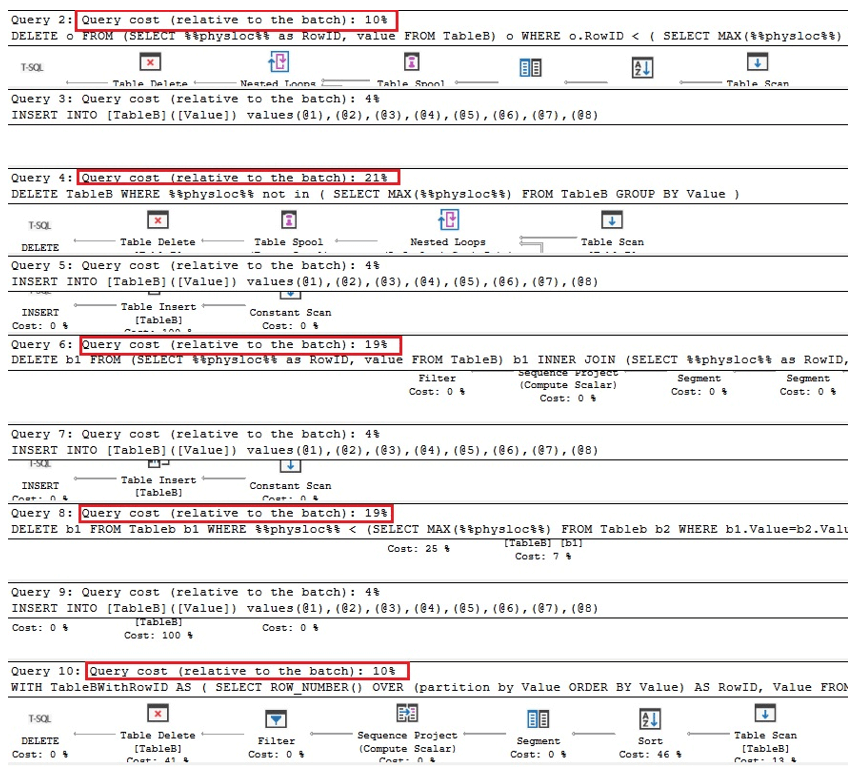
Daarom kunnen we concluderen dat het gebruik van %% physloc %% de prestatie in het algemeen niet verbetert. Bij het gebruik van deze benadering is het erg belangrijk om te beseffen dat dit een ongedocumenteerde functie van SQL Server is en daarom moeten ontwikkelaars zeer voorzichtig zijn.
Er zijn andere manieren om duplicaten te verwijderen die niet in deze tip worden besproken. We kunnen bijvoorbeeld afzonderlijke rijen in een tijdelijke tabel opslaan, vervolgens alle gegevens uit onze tabel verwijderen en daarna afzonderlijke rijen uit de tijdelijke tabel invoegen in onze permanente tabel. In dit geval moeten DELETE- en INSERT-instructies in één transactie worden opgenomen.
Conclusie
Tijdens onze ervaring komen we situaties tegen waarin we dubbele waarden uit SQL Server-tabellen moeten opschonen. De dubbele waarden kunnen in de kolom staan die wordt gedupliceerd op basis van onze vereisten, of de tabel kan dubbele rijen bevatten. In beide gevallen moeten we de gegevens uitsluiten om gegevensduplicatie in de database te voorkomen. In deze tip hebben we enkele technieken uitgelegd die hopelijk nuttig zullen zijn om dit soort problemen op te lossen.
Volgende stappen
Laatst bijgewerkt: 2019-08-16


Over de auteur
 Sergey Gigoyan is een databaseprofessional met meer dan 10 jaar ervaring, met een focus op databaseontwerp, -ontwikkeling, prestatieafstemming, optimalisatie, hoge beschikbaarheid, BI- en DW-ontwerp.
Sergey Gigoyan is een databaseprofessional met meer dan 10 jaar ervaring, met een focus op databaseontwerp, -ontwikkeling, prestatieafstemming, optimalisatie, hoge beschikbaarheid, BI- en DW-ontwerp. Bekijk al mijn tips
- Meer tips voor database-ontwikkelaars …