BFS와 DFS : 차이점 파악
BFS 란? ?
BFS는 데이터를 그래프로 표시하거나 트리를 검색하거나 구조를 탐색하는 데 사용되는 알고리즘입니다. 알고리즘은 정확한 폭 방식으로 그래프의 모든 주요 노드를 효율적으로 방문하고 표시합니다.
이 알고리즘은 그래프에서 단일 노드 (초기 또는 소스 지점)를 선택한 다음 선택한 노드에 인접한 모든 노드를 방문합니다. 알고리즘이 시작 노드를 방문하고 표시하면 가장 가까운 방문하지 않은 노드로 이동하여 분석합니다.
방문하면 모든 노드가 표시됩니다. 이러한 반복은 그래프의 모든 노드를 성공적으로 방문하고 표시 할 때까지 계속됩니다. BFS의 전체 형태는 Breadth-first 검색입니다.
이 BSF 대. DFS 바이너리 트리 자습서에서 배울 수 있습니다.
- BFS 란 무엇입니까?
- DFS 란 무엇입니까?
- BFS의 예
- DFS의 예
- BFS와 DFS 바이너리 트리의 차이점
- BFS의 응용 프로그램
- DFS의 응용 프로그램
DFS 란 무엇입니까?
DFS는 깊이 방향으로 그래프 또는 나무를 찾거나 탐색하는 알고리즘입니다. 알고리즘 실행은 루트 노드에서 시작하여 역 추적하기 전에 각 분기를 탐색합니다. 스택 데이터 구조를 사용하여 기억하고, 후속 정점을 가져오고, 모든 반복에서 막 다른 골목이 나타날 때마다 검색을 시작합니다. DFS의 전체 형식은 깊이 우선 검색입니다.
BFS의 예
다음 DFS의 예에서는 6 개의 꼭지점이있는 그래프를 사용했습니다.
BFS의 예
1 단계)

0 – 6 범위의 7 개 숫자 그래프가 있습니다.
2 단계)

0 또는 0이 루트 노드로 표시되었습니다.
3 단계)

0 개 방문, 표시 , 큐 데이터 구조에 삽입됩니다.
4 단계)

인접 및 방문하지 않은 나머지 0 명 노드를 방문하고, 표시하고, 대기열에 삽입합니다.
5 단계)

순회 반복은 다음까지 반복됩니다. 모든 노드를 방문합니다.
DFS 예제
다음 DFS 예제에서는 5 개의 정점이있는 무 방향 그래프를 사용했습니다.

1 단계)

우리는 정점 0에서 시작했습니다. 알고리즘은 방문 목록에 넣고 동시에 모든 인접 정점을 데이터에 넣는 것으로 시작합니다. 스택이라는 구조.
2 단계)
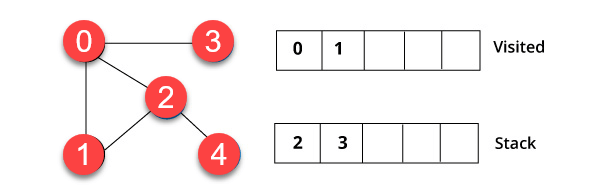
요소를 방문합니다. , 예를 들어 1과 같이 스택의 맨 위에 있으며 인접한 노드로 이동합니다. 0이 이미 방문했기 때문입니다. 따라서 정점 2를 방문합니다.
3 단계)

Vertex 2는 4의 근처에 방문하지 않은 정점을 가지고 있습니다. 따라서 스택에 추가하고 방문합니다.
4 단계)

마지막으로 마지막 정점 3에는 “방문하지 않은 인접 노드가 없습니다. DFS 알고리즘을 사용하여 그래프 순회를 완료했습니다.

BFS와 DFS 바이너리 트리의 차이점
| BFS | DFS |
| BFS는 대상까지의 최단 경로를 찾습니다. | DFS는 하위 트리의 맨 아래로 이동 한 다음 역 추적합니다. . |
| BFS의 전체 형태는 Breadth-First Search입니다. | DFS의 전체 형태는 Depth First Search입니다. |
| 다음 방문 위치를 추적하기 위해 대기열을 사용합니다. | 다음 방문 위치를 추적하기 위해 스택을 사용합니다. |
| BFS는 트리 레벨에 따라 순회합니다. | DFS는 트리 깊이에 따라 순회합니다. |
| FI를 사용하여 구현됩니다. FO 목록. | LIFO 목록을 사용하여 구현됩니다. |
| DFS에 비해 더 많은 메모리가 필요합니다. | BFS에 비해 적은 메모리가 필요합니다. |
| 이 알고리즘은 가장 얕은 경로 솔루션을 제공합니다. | 이 알고리즘은 “가장 얕은 경로 솔루션을 보장하지 않습니다. |
| BFS에서 역 추적 할 필요가 없습니다. | DFS에서 역 추적이 필요합니다. |
| 유한 루프에 갇힐 수는 없습니다. | 무한 루프에 갇힐 수 있습니다. |
| 목표를 찾지 못하면 솔루션을 찾기 전에 많은 노드를 확장해야 할 수 있습니다. | 목표를 찾지 못하면 리프 노드 역 추적이 가능합니다. 나오다. |
BFS의 애플리케이션
여기에 BFS의 애플리케이션이 있습니다.
비가 중 그래프 :
BFS 알고리즘은 가장 짧은 경로와 최소 스패닝 트리를 쉽게 생성하여 최대한 짧은 시간에 높은 정확도로 그래프의 모든 정점을 방문 할 수 있습니다.
P2P 네트워크 :
BFS는 P2P 네트워크에서 가장 가까운 노드 나 인접 노드를 모두 찾기 위해 구현 될 수 있습니다. 이렇게하면 필요한 데이터를 더 빨리 찾을 수 있습니다.
웹 크롤러 :
검색 엔진 또는 웹 크롤러는 BFS를 사용하여 여러 수준의 색인을 쉽게 구축 할 수 있습니다. BFS 구현은 웹 페이지 인 소스에서 시작하여 해당 소스의 모든 링크를 방문합니다.
네트워크 브로드 캐스트 :
브로드 캐스트 된 패킷은 주소가있는 모든 노드를 찾아 도달하기 위해 BFS 알고리즘에 의해 안내됩니다.
DFS 응용 프로그램
다음은 DFS의 중요한 응용 프로그램입니다.
가중 그래프 :
가중 그래프에서 DFS 그래프 순회 생성 최단 경로 트리 및 최소 스패닝 트리.
그래프에서 사이클 감지 :
DFS 중에 백 에지를 발견하면 그래프에 사이클이 있습니다. 따라서 그래프에 대해 DFS를 실행하고 뒤쪽 가장자리를 확인해야합니다.
경로 찾기 :
두 꼭지점 사이의 경로를 검색하는 DFS 알고리즘을 전문화 할 수 있습니다.
토폴로지 정렬 :
주로 작업 그룹간에 지정된 종속성에서 작업을 예약하는 데 사용됩니다. 컴퓨터 과학에서는 명령어 스케줄링, 데이터 직렬화, 논리 합성, 컴파일 작업 순서 결정에 사용됩니다.
그래프의 강하게 연결된 구성 요소 검색 :
그래프의 모든 정점에서 나머지 다른 정점까지 경로가있을 때 DFS 그래프에서 사용됩니다.
단 하나의 솔루션으로 퍼즐 풀기 :
DFS 알고리즘은 방문한 세트의 기존 경로에있는 노드를 포함하여 미로에 대한 모든 솔루션을 검색하도록 쉽게 조정할 수 있습니다.
주요 차이점 :
- BFS는 목적지까지의 최단 경로를 찾는 반면 DFS는 하위 트리의 맨 아래로 이동 한 다음 역 추적합니다.
- BFS의 전체 형식은 Breadth-First Search이고 DFS의 전체 형식은 Depth First Search입니다.
- BFS는 대기열을 사용하여 다음 방문 위치를 추적합니다. DFS는 다음 방문 위치를 추적하기 위해 스택을 사용합니다.
- BFS는 트리 수준에 따라 이동하는 반면 DFS는 트리 깊이에 따라 이동합니다.
- BFS는 FIFO 목록을 사용하여 구현됩니다. 반면 DFS는 LIFO 목록을 사용하여 구현됩니다.
- BFS에서는 유한 루프에 갇힐 수 없지만 DFS에서는 무한 루프에 갇힐 수 있습니다.