SQL Server 테이블에서 중복 행 찾기 및 제거
작성자 : Sergey Gigoyan | 업데이트 날짜 : 2019 년 8 월 16 일 | 댓글 (11) | 관련 : 기타 > 데이터베이스 설계
문제
데이터베이스 설계 모범 사례에 따르면 SQL Server 테이블에는 중복 행이 포함되어서는 안됩니다. 데이터베이스 디자인 프로세스 중에 중복 행을 제거하기 위해 기본 키를 만들어야합니다. 그러나 때때로 우리는 이러한 규칙을 따르지 않거나 예외가 가능한 (이 규칙이 의도적으로 우회되는 경우) 데이터베이스로 작업해야합니다. 예를 들어, 스테이징 테이블을 사용하고 중복 행이 가능한 다른 소스에서 데이터를로드하는 경우로드 프로세스가 완료되면 테이블을 정리하거나 정리 된 데이터를 영구 테이블에로드해야 더 이상 중복이 필요하지 않습니다. 따라서 로딩 테이블에서 중복 제거와 관련된 문제가 발생합니다. 이 팁에서는 데이터 중복 제거 요구를 해결하는 몇 가지 방법을 살펴 보겠습니다.
솔루션
이 팁에서는 두 가지 경우를 고려합니다.
- 첫 번째 경우는 SQL Server 테이블에 기본 키 (또는 고유 인덱스)가 있고 열 중 하나에 제거해야하는 중복 값이 포함되어있는 경우입니다.
- 두 번째 경우는 테이블에 기본 키가없는 경우입니다. 또는 제거해야하는 중복 행을 포함하고 있습니다. 이러한 경우를 별도로 논의하겠습니다.
SQL Server 테이블에서 중복 행을 제거하는 방법
SQL Server 테이블은 매우 심각한 문제가 될 수 있습니다. 데이터가 중복되면 주문이 여러 번 처리되고보고 결과가 부정확 해지는 등의 문제가 발생할 수 있습니다. SQL Server에는 다음과 같은 특정 상황에 따라 테이블의 중복 레코드를 처리하는 여러 가지 방법이 있습니다.
- 고유 인덱스가있는 테이블-고유 인덱스가있는 테이블의 경우 다음을 사용할 수 있습니다. 인덱스는 중복 데이터를 식별 한 다음 중복 레코드를 제거합니다. 식별은 자체 조인, 최대 값으로 데이터 정렬, RANK 함수 사용 또는 NOT IN 논리를 사용하여 수행 할 수 있습니다.
- 고유 인덱스가없는 테이블-고유 인덱스가없는 테이블의 경우 조금 더 많습니다. 도전적인. 이 시나리오에서 ROW_NUMBER () 함수를 공통 테이블 표현식 (CTE)과 함께 사용하여 데이터를 정렬 한 다음 후속 중복 레코드를 삭제할 수 있습니다.
실제 예제를 보려면 아래 예제를 확인하십시오. 테이블에서 중복 레코드를 삭제하는 방법에 대해 설명합니다.
고유 인덱스가있는 SQL Server 테이블에서 중복 행을 제거
테스트 환경 설정
작업을 수행하려면 테스트 환경이 필요합니다.
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
이제 “TableA”에 데이터를 삽입하겠습니다.
값 3과 5가 “값”열에 두 번 이상 존재하는 것을 볼 수 있습니다.
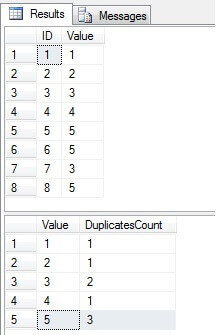
중복 행 식별 SQL Server 테이블
우리의 임무는 중복을 제거하여 “값”열에 대한 고유성을 적용하는 것입니다. 고유 인덱스가있는 테이블에서 중복 값을 제거하는 것은 인덱스가없는 테이블에서 행을 제거하는 것보다 약간 쉽습니다. 무엇보다도 중복을 찾아야합니다.이를 수행하는 방법에는 여러 가지가 있습니다. 몇 가지 일반적인 방법을 조사하고 비교합니다. 아래 코드에는 삭제해야하는 중복 값을 찾을 수있는 6 가지 솔루션이 있습니다 (하나의 값만 남김) :
모든 경우에 대한 결과가 동일하다는 것을 알 수 있습니다.
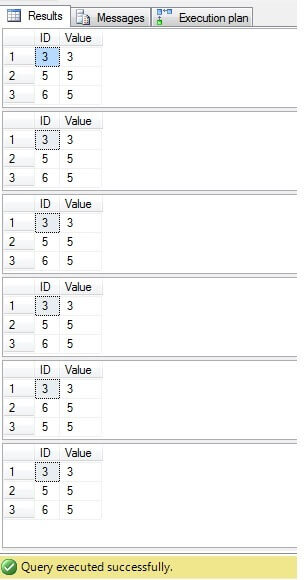
ID = 3, 5, 6 인 행만 삭제하면됩니다. 실행 계획을 살펴보면 가장 “간단한”솔루션 ( “솔루션 6”)이 가장 높은 비용 (이 예에서는 “ID”열에 기본 키가 있으므로 “NULL”값은 따라서 “NOT IN”열은 문제없이 작동 함) 두 번째 열의 비용이 가장 낮습니다.

삭제 SQL Server 테이블의 중복 행
이제 이러한 쿼리를 사용하여 테이블에서 중복 값을 삭제하겠습니다. 프로세스를 단순화하기 위해 두 번째, 다섯 번째 및 여섯 번째 쿼리 만 사용합니다.
데이터를 삭제하고 실행 계획을 다시 살펴보면 가장 빠른 것이 첫 번째 DELETE 명령이고 가장 느린 것이 예상대로 마지막 명령임을 알 수 있습니다.
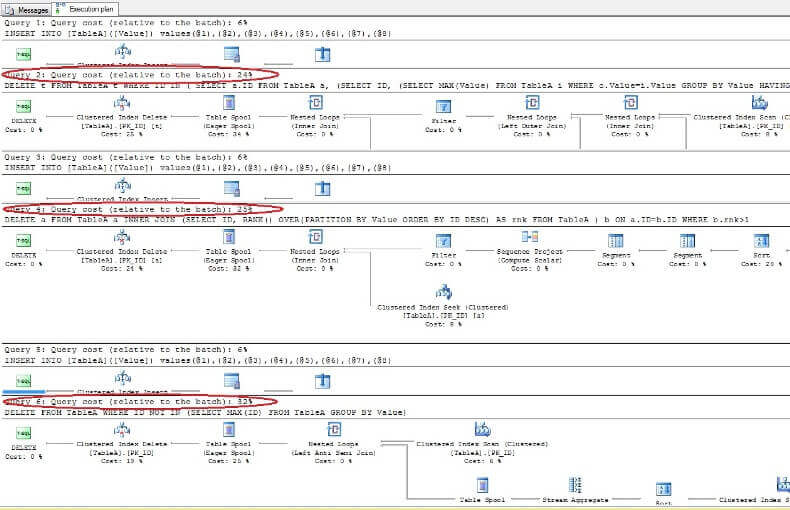
ORACLE에서 고유 한 인덱스가없는 테이블에서 중복 제거
이 팁의 마지막 예제를 설명하기위한 수단으로 Oracle의 유사한 기능 몇 가지를 설명하겠습니다. t에서 행 고유 인덱스가없는 기능은 SQL Server보다 Oracle에서 조금 더 쉽습니다. Oracle에는 행의 주소를 반환하는 ROWID 의사 열이 있습니다. 테이블의 행을 고유하게 식별합니다 (일반적으로 데이터베이스에도 있지만이 경우 예외가 있습니다. 다른 테이블이 동일한 클러스터에 데이터를 저장하는 경우 동일한 ROWID를 가질 수 있음).아래 쿼리는 Oracle 데이터베이스의 테이블에 데이터를 생성하고 삽입합니다.
이제 테이블에서 데이터와 ROWID를 선택합니다.
SELECT ROWID, Value FROM TableB;
결과는 다음과 같습니다.
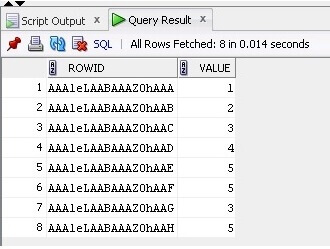
이제 ROWID를 사용하여 중복 행을 쉽게 제거 할 수 있습니다. table :
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
아래 코드를 사용하여 중복 항목을 제거 할 수도 있습니다.
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
고유 인덱스가없는 SQL Server 테이블에서 중복 제거
Oracle과 달리 SQL Server에는 ROWID가 없으므로 테이블에서 중복 제거 고유 색인 생성을 위해 추가 작업을 수행해야하는 고유 색인 :
위 코드에서 중복 행이있는 테이블을 만듭니다. ROW_NUMBER () 함수를 사용하여 고유 식별자를 생성하고 공통 테이블 표현식 (CTE)을 사용하여 중복을 삭제합니다.
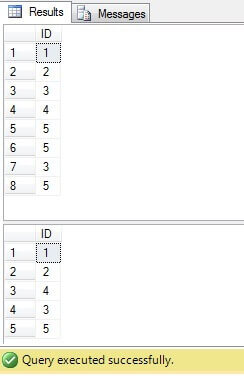
그러나이 코드는보다 간결하고 최적의 코드로 대체 할 수 있습니다.
하지만 SQL Server 행의 실제 주소도 식별 할 수 있습니다. 이 기능에 대한 공식 문서를 찾는 것이 사실상 불가능하다는 사실에도 불구하고 Oracle에서 ROWIDpseudo 열과 유사하게 사용할 수 있습니다. %% physloc %% (SQL Server 2008부터)라고하며 행의 실제 위치를 표시하는 가상 바이너리 (8) 열입니다. %% physloc %%의 값은 각 행에 대해 고유하므로 고유 인덱스가없는 테이블에서 중복 행을 제거하는 동안 행 식별자로 사용할 수 있습니다. 따라서 Oracle과 마찬가지로 SQL Server에서 고유 인덱스가없는 테이블에서 중복 행을 제거 할 수 있습니다.
아래의 처음 두 쿼리는 Oracle에서 중복을 제거하는 것과 동일한 버전이고 다음 두 쿼리는 고유 인덱스가있는 테이블의 경우와 유사하게 %% physloc %%를 사용하여 중복을 제거하는 쿼리입니다. 쿼리, %% physloc %%는 이러한 모든 옵션의 성능을 비교하는 데만 사용되지 않습니다.
실행 계획을 분석하면 전체 일괄 처리와 비교할 때 첫 번째 쿼리와 마지막 쿼리가 가장 빠르다는 것을 알 수 있습니다. 시간 :
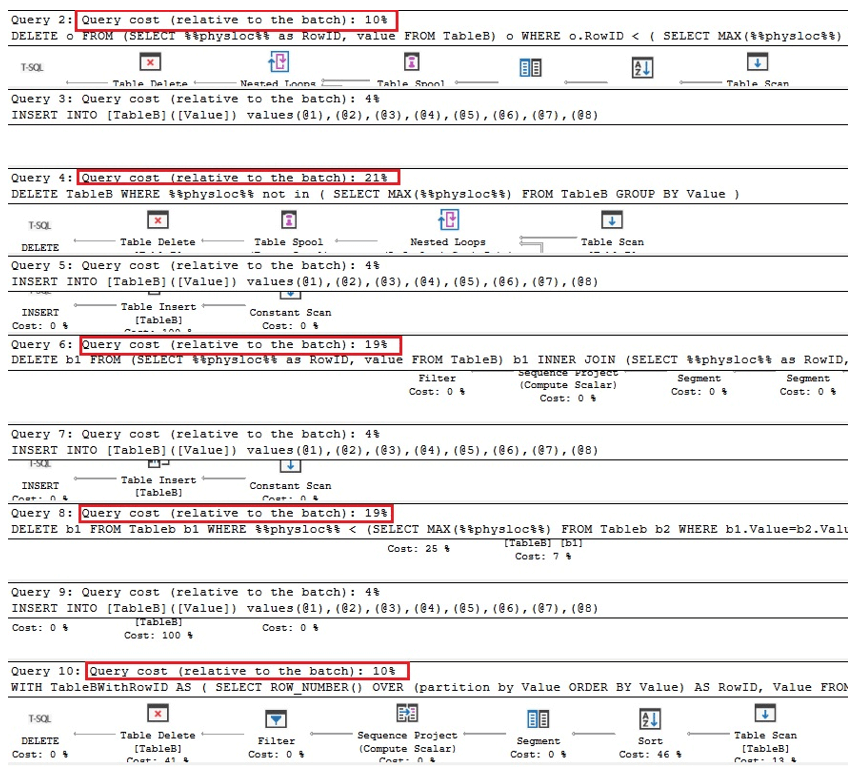
따라서 일반적으로 %% physloc %%를 사용해도 성능이 향상되지 않는다는 결론을 내릴 수 있습니다. 이 접근 방식을 사용하는 동안 이것이 SQL Server의 문서화되지 않은 기능임을 인식하는 것이 매우 중요하므로 개발자는 매우주의해야합니다.
이 팁에서 설명하지 않는 중복을 제거하는 다른 방법이 있습니다. 예를 들어, 임시 테이블에 고유 한 행을 저장 한 다음 테이블에서 모든 데이터를 삭제 한 다음 임시 테이블에서 영구 테이블로 고유 한 행을 삽입 할 수 있습니다. 이 경우 DELETE 및 INSERT 문이 하나의 트랜잭션에 포함되어야합니다.
결론
경험 중에 SQL Server 테이블에서 중복 값을 정리해야하는 상황에 직면했습니다. 중복 값은 요구 사항에 따라 중복 제거 될 열에 있거나 테이블에 중복 행이 포함될 수 있습니다. 두 경우 모두 데이터베이스에서 데이터 중복을 방지하기 위해 데이터를 제외해야합니다.이 팁에서는 이러한 유형의 문제를 해결하는 데 도움이되는 몇 가지 기술을 설명했습니다.
다음 단계
최종 업데이트 : 2019-08-16


작성자 정보
 Sergey Gigoyan은 데이터베이스 설계, 개발, 성능 튜닝, 최적화, 고 가용성, BI 및 DW 설계에 중점을 둔 10 년 이상의 경험을 가진 데이터베이스 전문가입니다.
Sergey Gigoyan은 데이터베이스 설계, 개발, 성능 튜닝, 최적화, 고 가용성, BI 및 DW 설계에 중점을 둔 10 년 이상의 경험을 가진 데이터베이스 전문가입니다. 내 모두보기 팁
- 추가 데이터베이스 개발자 팁 …