BFSとDFS:違いを知る
BFSとは?
BFSは、データのグラフ化、ツリーの検索、構造のトラバースに使用されるアルゴリズムです。アルゴリズムは、グラフ内のすべての主要ノードに効率的にアクセスして、正確な幅広の方法でマークを付けます。
このアルゴリズムは、グラフ内の単一のノード(初期ポイントまたはソースポイント)を選択してから、選択したノードに隣接するすべてのノードにアクセスします。アルゴリズムが開始ノードにアクセスしてマークを付けると、最も近い未アクセスのノードに向かって移動し、それらを分析します。
訪問すると、すべてのノードにマークが付けられます。これらの反復は、グラフのすべてのノードに正常にアクセスしてマークが付けられるまで続きます。 BFSの完全な形式は、幅優先探索です。
このBSFとDFSバイナリツリーチュートリアルでは、次のことを学習します。
- BFSとは何ですか?
- DFSとは何ですか?
- BFSの例
- DFSの例
- BFSとDFSバイナリツリーの違い
- BFSのアプリケーション
- DFSのアプリケーション
DFSとは何ですか?
DFSは、グラフまたはツリーを深さ方向に検索またはトラバースするためのアルゴリズムです。アルゴリズムの実行はルートノードから始まり、バックトラックする前に各ブランチを探索します。スタックデータ構造を使用して、反復で行き止まりが発生するたびに、記憶し、後続の頂点を取得し、検索を開始します。 DFSの完全な形式は、深さ優先探索です。
BFSの例
次のDFSの例では、 6つの頂点を持つグラフを使用しました。
BFSの例
ステップ1)

0〜6の範囲の7つの数値のグラフがあります。
ステップ2)

0またはゼロがルートノードとしてマークされています。
ステップ3)

0にアクセスし、マークを付けます、およびキューのデータ構造に挿入されます。
ステップ4)

隣接して未訪問のまま0ノードが訪問され、マークが付けられ、キューに挿入されます。
ステップ5)

トラバースの反復は、次のようになるまで繰り返されます。すべてのノードが訪問されます。
DFSの例
次のDFSの例では、5つの頂点を持つ無向グラフを使用しました。

ステップ1)

頂点0から開始しました。アルゴリズムは、頂点0を訪問先リストに配置すると同時に、隣接するすべての頂点をデータに配置することから始まります。スタックと呼ばれる構造。
ステップ2)
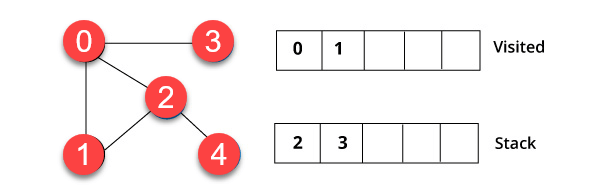
要素にアクセスします、たとえば1のスタックの最上位にあり、隣接するノードに移動します。すでに0を訪れているからです。したがって、頂点2にアクセスします。
ステップ3)

Vertex 2には、4に未訪問の近くの頂点があります。したがって、それをスタックに追加して訪問します。
ステップ4)

最後に、次のサイトにアクセスします。最後の頂点3には、「未訪問の隣接ノードはありません。DFSアルゴリズムを使用してグラフの走査を完了しました。

BFSとDFSバイナリツリーの違い
| BFS | DFS |
| BFSは宛先への最短パスを見つけます。 | DFSはサブツリーの一番下に移動し、その後バックトラックします。 。 |
| BFSの完全な形式はBreadth-FirstSearchです。 | DFSの完全な形式はDepthFirstSearchです。 |
| キューを使用して次に訪問する場所を追跡します。 | スタックを使用して次に訪問する場所を追跡します。 |
| BFSはツリーレベルに従ってトラバースします。 | DFSはツリーの深さに従ってトラバースします。 |
| FIを使用して実装されます。 FOリスト。 | LIFOリストを使用して実装されます。 |
| DFSと比較してより多くのメモリが必要です。 | BFSと比較して必要なメモリが少なくて済みます。 |
| このアルゴリズムは、最も浅いパスソリューションを提供します。 | このアルゴリズムは、最も浅いパスのソリューションを保証するものではありません。 |
| BFSでバックトラックする必要はありません。 | あります。 DFSでのバックトラックの必要性。 |
| 有限ループに閉じ込められることは決してありません。 | 無限ループに閉じ込められる可能性があります。 |
| 目標が見つからない場合は、ソリューションが見つかる前に多くのノードを展開する必要がある場合があります。 | 目標が見つからない場合は、リーフノードのバックトラックが発生する可能性があります。発生する。 |
BFSのアプリケーション
ここに、BFSのアプリケーションがあります:
重み付けなしグラフ:
BFSアルゴリズムは、最短パスと最小スパニングツリーを簡単に作成して、グラフのすべての頂点に最短時間で高精度でアクセスできます。
P2Pネットワーク:
BFSを実装して、ピアツーピアネットワーク内の最も近いノードまたは隣接するノードをすべて見つけることができます。これにより、必要なデータがより早く見つかります。
Webクローラー:
検索エンジンまたはWebクローラーは、BFSを使用することで複数レベルのインデックスを簡単に作成できます。 BFSの実装は、Webページであるソースから開始し、次にそのソースからのすべてのリンクにアクセスします。
ネットワークブロードキャスト:
ブロードキャストされたパケットは、BFSアルゴリズムによってガイドされ、アドレスを持つすべてのノードを見つけて到達します。
DFSのアプリケーション
DFSの重要なアプリケーションは次のとおりです。
加重グラフ:
加重グラフでは、DFSグラフトラバーサルが生成します。最短パスツリーと最小スパニングツリー。
グラフ内のサイクルの検出:
DFS中にバックエッジが見つかった場合、グラフにはサイクルがあります。したがって、グラフに対してDFSを実行し、バックエッジを確認する必要があります。
経路探索:
DFSアルゴリズムに特化して、2つの頂点間の経路を検索できます。
トポロジカルソート:
主に、ジョブグループ間の特定の依存関係からジョブをスケジュールするために使用されます。コンピュータサイエンスでは、命令スケジューリング、データシリアル化、論理合成、コンパイルタスクの順序の決定に使用されます。
グラフの強連結成分の検索:
グラフ内のすべての頂点から他の残りの頂点へのパスがある場合に、DFSグラフで使用されます。
1つのソリューションのみでパズルを解く:
DFSアルゴリズムは、訪問したセットに既存のパス上のノードを含めることで、迷路のすべてのソリューションを検索するように簡単に適合させることができます。
主な違い:
- BFSは宛先への最短パスを見つけますが、DFSはサブツリーの一番下に移動してからバックトラックします。
- BFSの完全な形式は幅優先探索ですがDFSの完全な形式は深さ優先探索です。
- BFSはキューを使用して、次に訪問する場所を追跡します。一方、DFSはスタックを使用して、次にアクセスする場所を追跡します。
- BFSはツリーレベルに従ってトラバースし、DFSはツリーの深さに従ってトラバースします。
- BFSはFIFOリストを使用して実装されます。一方、DFSはLIFOリストを使用して実装されます。
- BFSでは、有限ループにトラップされることはありませんが、DFSでは、無限ループにトラップされる可能性があります。