SQLServerテーブルから重複する行を見つけて削除する
作成者:Sergey Gigoyan |更新日:2019-08-16 |コメント(11)|関連:その他の>データベース設計
問題
databasedesignのベストプラクティスによると、SQLServerテーブルに重複する行を含めることはできません。データベースの設計プロセス中に、重複する行を排除するためにプライマリキーを作成する必要があります。ただし、これらのルールに従わない場合や例外が発生する可能性があるデータベースを操作する必要がある場合があります(これらのルールが意図的にバイパスされている場合)。たとえば、ステージングテーブルが使用され、重複行が発生する可能性のあるさまざまなソースからデータが読み込まれる場合、読み込みプロセスが完了したら、テーブルをクリーンアップするか、クリーンなデータを永続テーブルに読み込む必要があります。その後、重複は不要になります。したがって、ロードテーブルからの重複の削除に関する問題が発生します。このヒントでは、データ重複排除のニーズを解決するためのいくつかの方法を検討します。
解決策
このヒントでは、次の2つのケースを検討します。
- 最初のケースは、SQL Serverテーブルに主キー(または一意のインデックス)があり、列の1つに削除する必要のある重複値が含まれている場合です。
- 2番目のケースは、テーブルに主キーがない場合です。または任意のuniqueindexesであり、削除する必要のある重複行が含まれています。これらのケースについて個別に説明します。
SQLServerテーブルの重複行を削除する方法
SQLServerテーブルは非常に深刻な問題になる可能性があります。データが重複していると、注文が何度も処理されたり、レポートの結果が不正確になったりする可能性があります。 SQL Serverでは、特定の状況に基づいてテーブル内の重複レコードに対処する方法がいくつかあります。
- 一意のインデックスを持つテーブル-一意のインデックスを持つテーブルの場合、次のように使用できます。注文するインデックスは重複データを識別し、重複レコードを削除します。識別は、自己結合、最大値によるデータの順序付け、RANK関数、またはNOTINロジックを使用して実行できます。
- 一意のインデックスのないテーブル-一意のインデックスのないテーブルの場合、もう少しです。挑戦。このシナリオでは、ROW_NUMBER()関数をCommon Table Expression(CTE)とともに使用してデータを並べ替え、後続の重複レコードを削除できます。
以下の例を確認して、実際の例を取得してください。テーブルから重複レコードを削除する方法について。
一意のインデックスを持つSQLServerテーブルから重複行を削除する
テスト環境のセットアップ
タスクを実行するには、テスト環境が必要です:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
次に、「TableA」にデータを挿入しましょう:
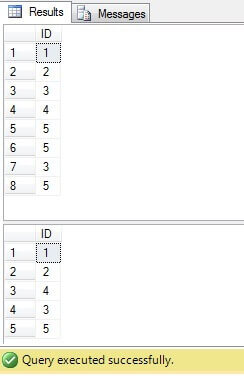
値3と5が[値]列に複数回存在していることがわかります。
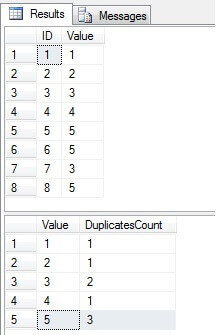
重複する行を特定するSQLServerテーブル
私たちのタスクは、重複を削除することで「値」列の一意性を強制することです。一意のインデックスを持つテーブルから重複する値を削除することは、それがないテーブルから行を削除するよりも少し簡単です。何よりも、重複を見つける必要があります。それを行うにはさまざまな方法があります。いくつかの一般的な方法を調査して比較します。以下のコードでは、削除する必要がある重複値を見つけるための6つの解決策があります(1つの値のみを残します):
すべての場合の結果は同じです:
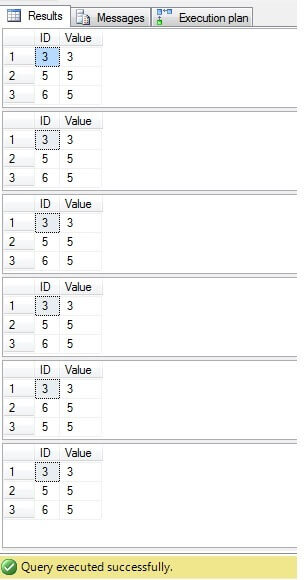
ID = 3、5、6の行のみを削除する必要があります。実行プランを見ると、最新の-最も「コンパクトな」ソリューション(「ソリューション6」)のコストが最も高いことがわかります(この例では、「ID」列に主キーがあるため、「NULL」値は使用できません。その列、したがって「NOT IN」は問題なく機能します)、2番目の列のコストは最も低くなります:

削除SQLServerテーブルの重複行
次に、これらのクエリを使用して、テーブルから重複値を削除しましょう。プロセスを簡略化するために、2番目、5番目、6番目のクエリのみを使用します。
データを削除して実行プランを再度調べると、予想どおり、最も速いものが最初のDELETEコマンドであり、最も遅いものが最後であることがわかります。
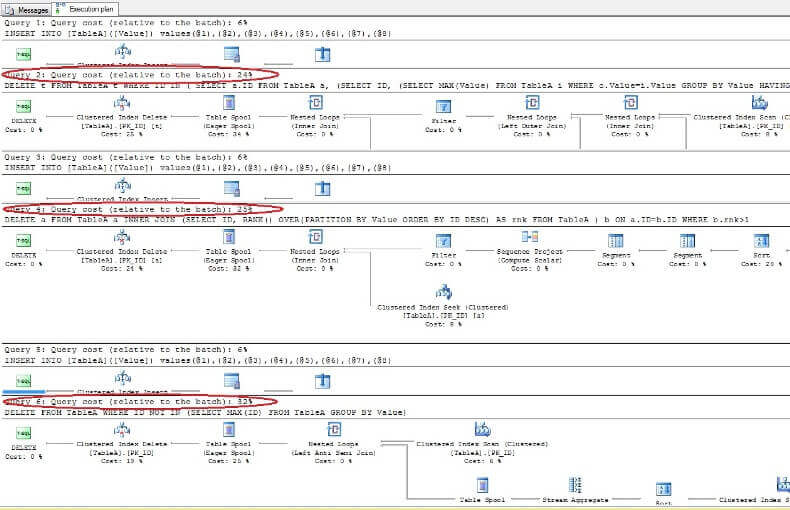
ORACLEで一意のインデックスのないテーブルから重複を削除する
このヒントの最後の例を説明するための手段として、Oracleのいくつかの同様の機能について説明します。重複の削除tからの行一意のインデックスなしで実行できるのは、SQLServerよりもOracleの方が少し簡単です。 Oracleには、行のアドレスを返すROWID疑似列があります。テーブル内の行を一意に識別します(通常はデータベース内でもありますが、この場合は例外があります。異なるテーブルが同じクラスターにデータを格納している場合、同じROWIDを持つことができます)。以下のクエリは、データを作成してOracleデータベースのテーブルに挿入します。
テーブルからデータとROWIDを選択します:
SELECT ROWID, Value FROM TableB;
結果は次のとおりです。
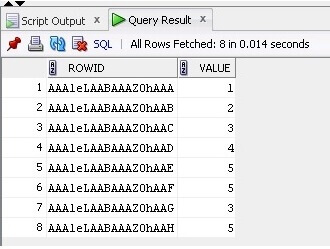
ROWIDを使用すると、重複する行を簡単に削除できます。表:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
以下のコードを使用して重複を削除することもできます:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
一意のインデックスのないSQLServerテーブルからの重複の削除
Oracleとは異なり、SQL ServerにはROWIDがないため、一意の行識別子を生成するために追加の作業を行う必要がある一意のインデックス:
上記のコードでは、重複する行を持つテーブルを作成しています。 ROW_NUMBER()関数を使用して一意の識別子を生成し、共通テーブル式(CTE)を使用して、重複を削除しています。
ただし、このコードは、よりコンパクトで最適なコードに置き換えることができます。
そうは言っても、SQLServerの行の物理アドレスを特定することもできます。この機能に関する公式のドキュメントを見つけることは事実上不可能ですが、OracleのROWIDpseudo列のアナログとして使用できます。これは%% physloc %%(SQL Server 2008以降)と呼ばれ、行の物理的な場所を示す仮想binary(8)列です。 %% physloc %%の値は行ごとに一意であるため、一意のインデックスのないテーブルから重複する行を削除するときに、これを行識別子として使用できます。したがって、Oracleの場合や、テーブルに一意のインデックスがある場合のように、SQLServerでは一意のインデックスのないテーブルから重複する行を削除できます。
以下の最初の2つのクエリは、Oracleで重複を削除するのと同等のバージョンであり、次の2つは、一意のインデックスを持つテーブルの場合と同様に、%% physloc %%を使用して重複を削除するためのクエリです。クエリ、%% physloc %%は、これらすべてのオプションのパフォーマンスを比較するためだけに使用されるわけではありません。
実行プランを分析すると、バッチ全体と比較した場合、最初と最後のクエリが最速であることがわかります。時間:
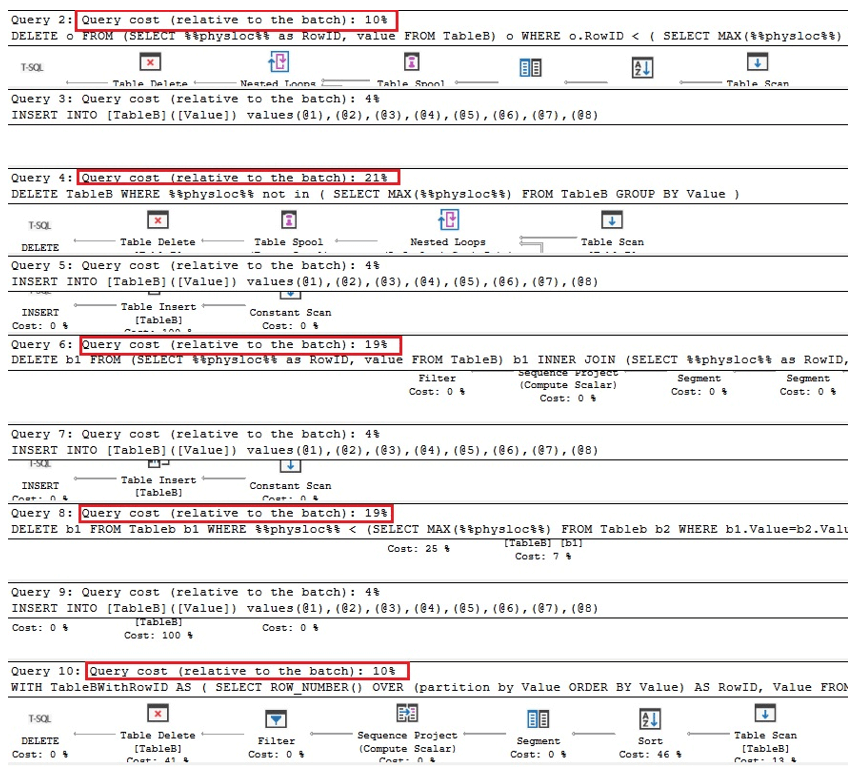
したがって、一般に、%% physloc %%を使用してもパフォーマンスは向上しないと結論付けることができます。このアプローチを使用する場合、これはSQL Serverの文書化されていない機能であるため、開発者は非常に注意する必要があることを理解することが非常に重要です。
このヒントで説明されていない重複を削除する方法は他にもあります。たとえば、個別の行を一時テーブルに格納してから、テーブルからすべてのデータを削除し、その後、一時テーブルから永続テーブルに個別の行を挿入できます。この場合、DELETEステートメントとINSERTステートメントを1つのトランザクションに含める必要があります。
結論
経験上、SQLServerテーブルから重複する値を削除する必要がある状況に直面します。重複する値は、要件に基づいて重複排除される列に含めることができます。または、テーブルに重複する行を含めることもできます。いずれの場合も、データベース内のデータの重複を避けるためにデータを除外する必要があります。このヒントでは、これらのタイプの問題を解決するのに役立つと思われるいくつかの手法について説明しました。
次のステップ
最終更新日:2019-08-16


作成者について
 Sergey Gigoyanは、データベースの設計、開発、パフォーマンスチューニング、最適化、高可用性、BIおよびDW設計に重点を置いた、10年以上の経験を持つデータベースの専門家です。
Sergey Gigoyanは、データベースの設計、開発、パフォーマンスチューニング、最適化、高可用性、BIおよびDW設計に重点を置いた、10年以上の経験を持つデータベースの専門家です。すべてを表示ヒント
- その他のデータベース開発者向けのヒント…