Trovare e rimuovere righe duplicate da una tabella di SQL Server
Di: Sergey Gigoyan | Aggiornato: 2019-08-16 | Commenti (11) | Correlati: Altro > Progettazione database
Problema
Secondo le migliori pratiche di progettazione di database, una tabella di SQL Server non dovrebbe contenere righe duplicate. Durante il processo di progettazione del database è necessario creare chiavi primarie per eliminare le righe duplicate. Tuttavia, a volte è necessario lavorare con database in cui queste regole non vengono seguite o sono possibili eccezioni (quando queste regole vengono ignorate consapevolmente). Ad esempio, quando viene utilizzata una tabella di staging e i dati vengono caricati da origini diverse in cui sono possibili righe duplicate. Al termine del processo di caricamento, la tabella deve essere pulita o i dati puliti dovrebbero essere caricati in una tabella permanente, quindi i duplicati non sono più necessari. Pertanto, sorge un problema relativo alla rimozione dei duplicati dal tavolo di caricamento. In questo suggerimento esaminiamo alcuni modi per risolvere le esigenze di deduplicazione dei dati.
Soluzione
Considereremo due casi in questo suggerimento:
- Il primo caso è quando una tabella di SQL Server ha una chiave primaria (o indice univoco) e una delle colonne contiene valori duplicati che dovrebbero essere rimossi.
- Il secondo caso è che la tabella non ha una chiave primaria o qualsiasi indice univoco e contiene righe duplicate che dovrebbero essere rimosse. Discutiamo questi casi separatamente.
Come rimuovere righe duplicate in una tabella di SQL Server
Record duplicati in una tabella di SQL Server può essere un problema molto serio. Con i dati duplicati è possibile che gli ordini vengano elaborati più volte, avere risultati non accurati per la reportistica e altro ancora. In SQL Server esistono diversi modi per indirizzare i record duplicati in una tabella in base a circostanze specifiche, ad esempio:
- Tabella con indice univoco: per le tabelle con un indice univoco, hai la possibilità di utilizzare lindice per ordinare identificare i dati duplicati, quindi rimuovere i record duplicati. Lidentificazione può essere eseguita con auto-join, ordinando i dati in base al valore massimo, utilizzando la funzione RANK o utilizzando la logica NOT IN.
- Tabella senza un indice univoco – Per le tabelle senza un indice univoco, è un po di più impegnativo. In questo scenario, la funzione ROW_NUMBER () può essere utilizzata con unespressione di tabella comune (CTE) per ordinare i dati, quindi eliminare i record duplicati successivi.
Dai unocchiata agli esempi seguenti per ottenere esempi del mondo reale su come eliminare i record duplicati da una tabella.
Rimozione di righe duplicate da una tabella SQL Server con un indice univoco
Configurazione dellambiente di prova
Per eseguire le nostre attività, abbiamo bisogno di un ambiente di test:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Ora inseriamo i dati in “TableA”:
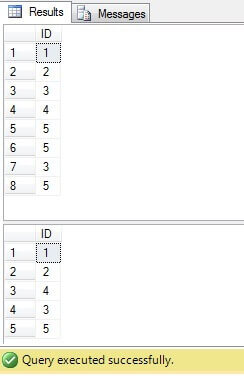
Come possiamo vedere, i valori 3 e 5 esistono più di una volta nella colonna “Valore”:
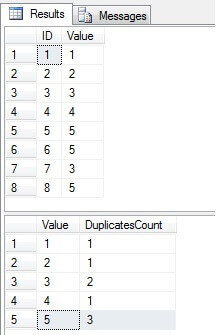
Identifica righe duplicate in una tabella di SQL Server
Il nostro compito è rafforzare lunicità della colonna “Valore” rimuovendo i duplicati. La rimozione di valori duplicati dalla tabella con un indice univoco è un po più semplice che rimuovere le righe da una tabella senza di essa. Innanzitutto di tutto, abbiamo bisogno di trovare duplicati. Ci sono molti modi diversi per farlo indagare e confrontare alcuni modi comuni. Nel codice sottostante ci sono sei soluzioni per trovare quei valori duplicati che dovrebbero essere eliminati (lasciando solo un valore):
Come possiamo vedere il risultato per tutti i casi è lo stesso:
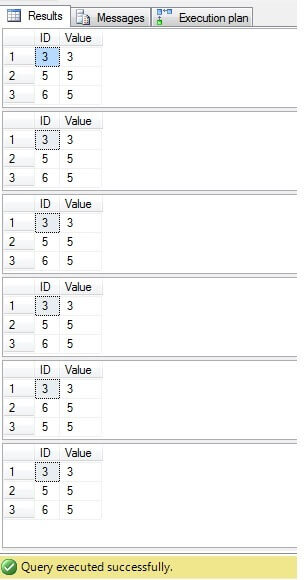
È necessario eliminare solo le righe con ID = 3, 5, 6. Guardando il piano di esecuzione possiamo vedere che lultima: la soluzione più “compatta” (“Soluzione 6”) ha un costo più alto (nel nostro esempio cè una chiave primaria nella colonna “ID”, quindi i valori “NULL” non sono possibili per quella colonna, quindi “NOT IN” funzionerà senza problemi), e la seconda ha il costo più basso:

Eliminazione Righe duplicate in una tabella di SQL Server
Ora utilizzando queste query, eliminiamo i valori duplicati dalla tabella. Per semplificare il nostro processo, utilizzeremo solo la seconda, la quinta e la sesta query:
Eliminando i dati e esaminando nuovamente i piani di esecuzione, vediamo che il più veloce è il primo comando DELETE e il più lento è lultimo come previsto:
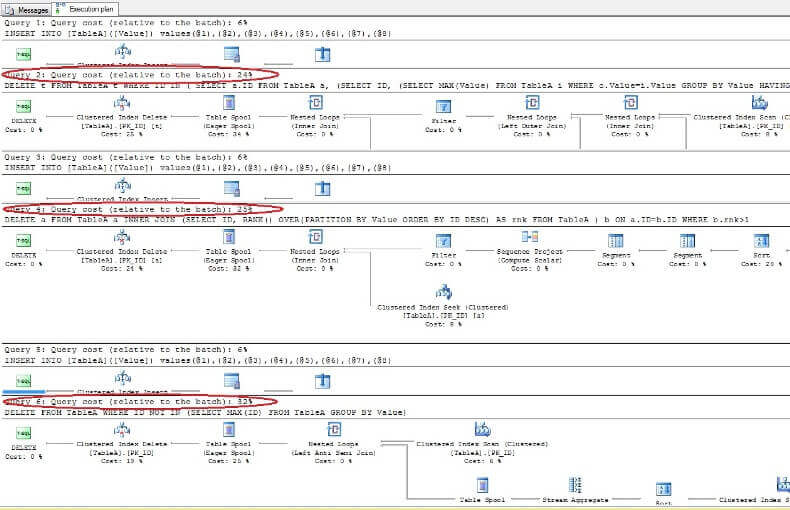
Rimozione di duplicati dalla tabella senza un indice univoco in ORACLE
Come mezzo per illustrare il nostro esempio finale in questo suggerimento, voglio spiegare alcune funzionalità simili in Oracle. Rimozione di duplicati righe dalla t abile senza un indice univoco è un po più semplice in Oracle che in SQL Server. Cè una pseudo colonna ROWID in Oracle che restituisce lindirizzo della riga. Identifica in modo univoco la riga nella tabella (di solito anche nel database, ma in questo caso cè uneccezione: se tabelle diverse archiviano dati nello stesso cluster, possono avere lo stesso ROWID).La query seguente crea e inserisce i dati nella tabella nel database Oracle:
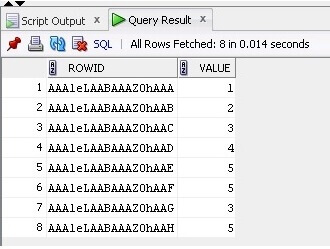
Ora stiamo selezionando i dati e ROWID dalla tabella:
SELECT ROWID, Value FROM TableB;
Il risultato è di seguito:
Ora utilizzando ROWID, rimuoveremo facilmente le righe duplicate da tabella:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Possiamo anche rimuovere i duplicati utilizzando il codice seguente:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Rimozione di duplicati da una tabella di SQL Server senza un indice univoco
A differenza di Oracle, non cè ROWID in SQL Server, quindi per rimuovere i duplicati dalla tabella senza un indice univoco di cui abbiamo bisogno per fare del lavoro aggiuntivo per generare identificatori uniquerow:
Nel codice sopra, stiamo creando una tabella con righe duplicate. Stiamo generando identificatori univoci utilizzando la funzione ROW_NUMBER () e utilizzando lespressione di tabella comune (CTE) stiamo eliminando i duplicati:
Questo codice, tuttavia, può essere sostituito con uno più compatto e ottimale:
Detto questo, è possibile identificare lindirizzo fisico del row anche in SQL Server. Nonostante sia praticamente impossibile trovare documentazione ufficiale su questa funzione, può essere utilizzata come analogo alla colonna ROWIDpseudo in Oracle. Si chiama %% physloc %% (da SQL Server 2008) ed è una colonna binaria virtuale (8) che mostra la posizione fisica della riga. Poiché il valore di %% physloc %% è univoco per ogni riga, possiamo usarlo come identificatore di riga durante la rimozione di righe duplicate da una tabella senza un indice univoco. Pertanto, possiamo rimuovere righe duplicate da una tabella senza un indice univoco in SQL Server come in Oracleas così come nel caso in cui la tabella abbia un indice univoco.
Le prime due query di seguito sono le versioni equivalenti della rimozione dei duplicati in Oracle, le due successive sono query per la rimozione dei duplicati utilizzando %% physloc %% simile al caso della tabella con un indice univoco e nellultima query, %% physloc %% non viene utilizzato solo per confrontare le prestazioni di tutte queste opzioni:
Analizzando i piani di esecuzione, possiamo vedere che la prima e lultima query sono le più veloci rispetto al batch complessivo volte:
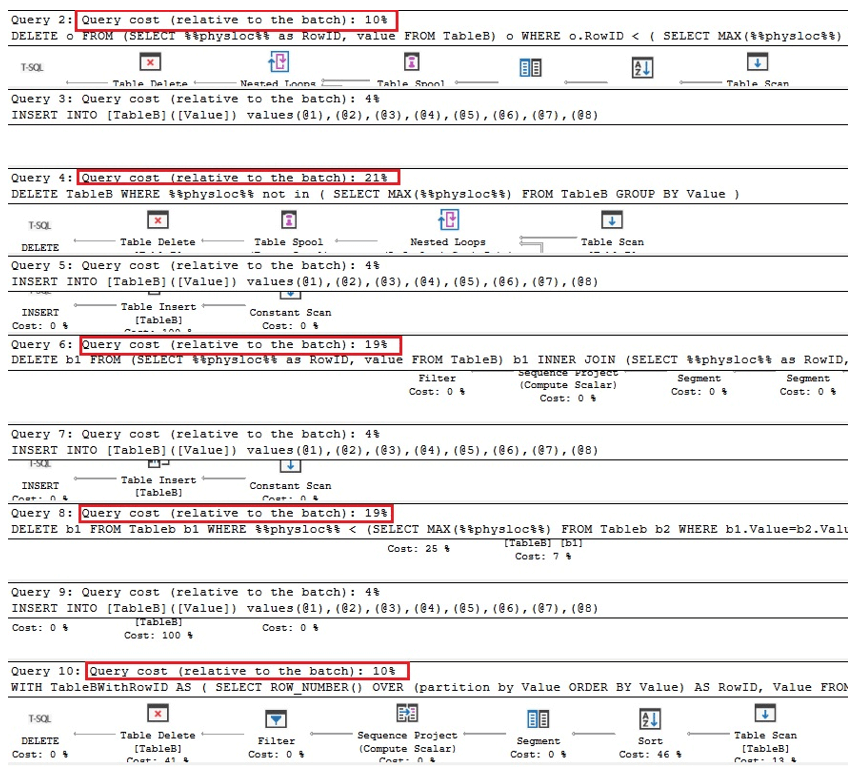
Quindi, possiamo concludere che in generale, luso di %% physloc %% non migliora le prestazioni. Durante lutilizzo di questo approccio, è molto importante rendersi conto che questa è una funzionalità non documentata di SQL Server e, quindi, gli sviluppatori dovrebbero essere molto attenti.
Ci sono altri modi per rimuovere i duplicati che non sono discussi in questo suggerimento. Ad esempio, possiamo memorizzare righe distinte in una tabella temporanea, quindi eliminare tutti i dati dalla nostra tabella e successivamente inserire righe distinte dalla tabella temporanea alla nostra tabella permanente. In questo caso, le istruzioni DELETE e INSERT dovrebbero essere incluse in una transazione.
Conclusione
Durante la nostra esperienza ci troviamo di fronte a situazioni in cui dobbiamo pulire i valori duplicati dalle tabelle di SQL Server. I valori duplicati possono essere nella colonna che verrà duplicata in base ai nostri requisiti oppure la tabella può contenere righe duplicate. In entrambi i casi dobbiamo escludere i dati per evitare la duplicazione dei dati nel database. In questo suggerimento abbiamo spiegato alcune tecniche che si spera possano essere utili per risolvere questi tipi di problemi.
Passaggi successivi
Ultimo aggiornamento: 16-08-2019


Informazioni sullautore
 Sergey Gigoyan è un professionista del database con più di 10 anni di esperienza, con un focus su progettazione di database, sviluppo, ottimizzazione delle prestazioni, ottimizzazione, alta disponibilità, progettazione BI e DW.
Sergey Gigoyan è un professionista del database con più di 10 anni di esperienza, con un focus su progettazione di database, sviluppo, ottimizzazione delle prestazioni, ottimizzazione, alta disponibilità, progettazione BI e DW. Visualizza tutti i miei suggerimenti
- Altri suggerimenti per sviluppatori di database …