Ismétlődő sorok megkeresése és eltávolítása az SQL Server táblából
Szerző: Sergey Gigoyan | Frissítve: 2019-08-16 | Megjegyzések (11) Kapcsolódó: További > Adatbázis-tervezés
Probléma
A legjobb adatbázis-tervezési gyakorlatok szerint az SQL Server-tábla nem tartalmazhat ismétlődő sorokat. Az adatbázis-tervezési folyamat során az elsődleges kulcsokat kell létrehozni az ismétlődő sorok kiküszöbölésére. Néha azonban olyan adatbázisokkal kell dolgoznunk, ahol ezeket a szabályokat nem tartják be, vagy kivételek lehetségesek (amikor ezeket a szabályokat tudatosan megkerülik). Például, ha egy átmeneti táblát használnak, és az adatokat különböző forrásokból töltik be, ahol ismétlődő sorok lehetségesek. A betöltési folyamat befejeztével a táblázatot meg kell tisztítani, vagy a tiszta adatokat be kell tölteni egy állandó táblába, így ezek után többé nincs szükség. Ezért felmerül a duplikátumok eltávolításának kérdése a betöltési tábláról. Ebben a tippben vizsgáljuk meg az adatok duplikációs szükségleteinek megoldási módjait.
Megoldás
Ebben a tippben két esetet veszünk figyelembe:
- Az első eset az, amikor az SQL Server táblának van elsődleges kulcsa (vagy egyedi indexe), és az egyik oszlop duplikált értékeket tartalmaz, amelyeket el kell távolítani.
- A második eset az, hogy a táblában nincs elsődleges kulcs vagy bármely egyedi indexet tartalmaz, és duplikált sorokat tartalmaz, amelyeket el kell távolítani. Döntsék el ezeket az eseteket külön.
Hogyan távolítsuk el az ismétlődő sorokat az SQL Server táblából
Rekordok duplikálása itt: egy SQL Server tábla nagyon komoly problémát jelenthet. Ismétlődő adatokkal lehetőség van a megrendelések sokszoros feldolgozására, pontatlan eredményekkel a jelentésekre és egyebekre. Az SQL Server szolgáltatásban számosféle módon kezelhetők a duplikált rekordok a táblázatban az adott körülmények alapján, például:
- Táblázat egyedi indexszel – Egyedi indexű táblák esetén lehetősége van használni az index a duplikált adatok azonosításához, majd távolítsa el az ismétlődő rekordokat. Az azonosítás elvégezhető önillesztésekkel, az adatok maximális érték szerinti sorrendjével, a RANK funkcióval vagy a NOT IN logikával.
- Táblázat egyedi index nélkül – egyedi index nélküli táblák esetében ez még egy kicsit több. kihívást jelentő. Ebben a forgatókönyvben a ROW_NUMBER () függvény használható egy közös tábla kifejezéssel (CTE) az adatok rendezéséhez, majd a későbbi ismétlődő rekordok törléséhez.
Nézze meg az alábbi példákat, hogy valós példákat kapjon. a duplikaterecerek törléséről a tábláról.
Az ismétlődő sorok eltávolítása az egyedi indexű SQL Server táblából
Tesztkörnyezet beállítása
Feladataink elvégzéséhez tesztkörnyezetre van szükségünk:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Most adjuk be az adatokat az “A tábla” -ba:
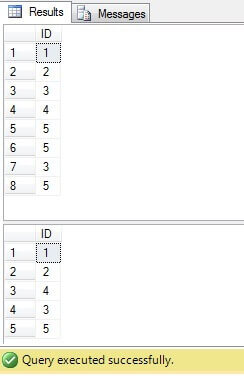
Amint láthatjuk, a 3. és 5. érték többször létezik az “Érték” oszlopban:
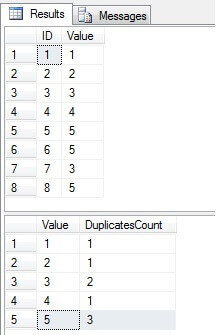
Ismétlődő sorok azonosítása egy SQL Server táblázat
Feladatunk az “Érték” oszlop egyediségének kikényszerítése az ismétlődések eltávolításával. A duplikált értékek eltávolítása az egyedi indexű táblákból kissé könnyebb, mint a sorok eltávolítása egy tábla nélkül. Mindenekelőtt meg kell találnunk a másolatokat. Ennek sokféle módja van. Legyen Vizsgálja meg és hasonlítsa össze néhány általános módszert. Az alábbi kódban hat megoldás létezik annak megállapítására, hogy az ismétlődő értékeket törölni kell (csak egy értéket hagyva):
Mint láthatjuk, az összes eset eredménye ugyanaz:
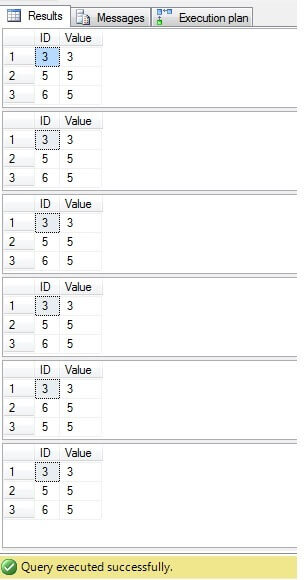
Csak az ID = 3, 5, 6 sorokat kell törölni. A végrehajtási tervet nézve nem lehet látni, hogy a legújabb – a “legkompaktabb” megoldás (“6. megoldás”) költségei a legmagasabbak (példánkban az “ID” oszlopban található egy elsődleges kulcs, így a “NULL” értékek nem lehetségesek ez az oszlop, ezért a “NOT IN” probléma nélkül fog működni), és a második költsége a legalacsonyabb:

Törlés Sorok duplikálása az SQL Server táblában
Ezeknek a lekérdezéseknek a használatával töröljük az ismétlődő értékeket a táblából. A folyamat egyszerűsítése érdekében csak a második, az ötödik és a hatodik lekérdezést fogjuk használni:
Az adatok törlésével és a végrehajtási tervek újbóli áttekintésével azt látjuk, hogy a leggyorsabb az első DELETE parancs, a leglassabb pedig az utolsó, a várakozásoknak megfelelően:
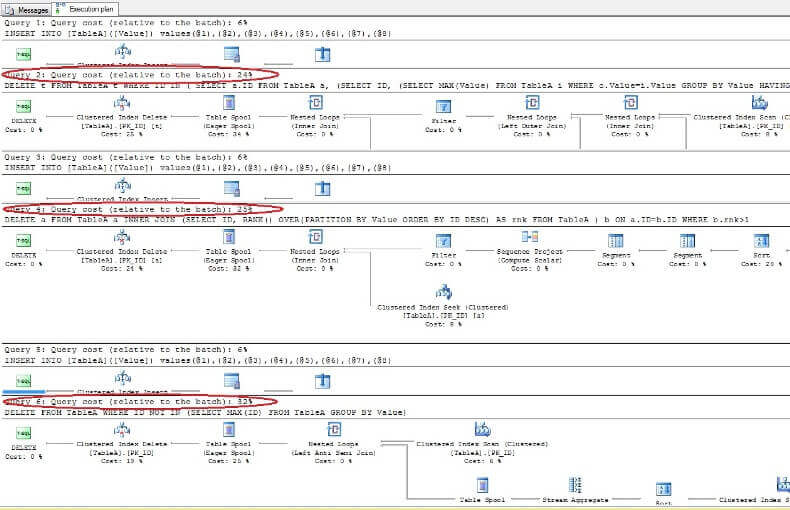
Ismétlődések eltávolítása az ORACLE-ből egyedi index nélküli táblázatból
Ennek a tippnek a végső példájának bemutatásához néhány hasonló funkciót szeretnék elmagyarázni az Oracle-ben. sorok a t Az egyedi index nélkül képes az Oracle-nél valamivel könnyebb, mint az SQL Server-en. Az Oracle-ben van egy ROWID áloszlop, amely visszaadja a sor címét. Egyedileg azonosítja a táblázat sorát (általában az adatbázisban is, de ebben az esetben van kivétel) – ha a különböző táblák ugyanazon klaszterben tárolják az adatokat, akkor ugyanaz a ROWID lehet.Az alábbi lekérdezés létrehoz és beilleszt adatokat az Oracle adatbázis táblájába:
Most az adatokat és a ROWID-t választjuk ki a táblából:
SELECT ROWID, Value FROM TableB;
Az eredmény az alábbiakban látható:
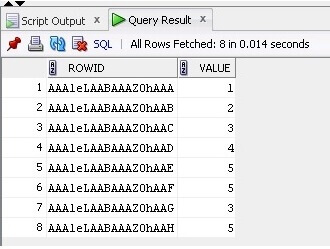
Most a ROWID használatával könnyen eltávolítjuk a duplikált sorokat táblázat:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
A duplikátumokat az alábbi kód segítségével is eltávolíthatjuk:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Ismétlődések eltávolítása az SQL Server táblából egyedi index nélkül
Az Oracle-től eltérően nincs ROWID az SQL Serverben, így a duplikátumok eltávolításához a táblából egyedi index, további munkát kell végeznünk az uniquerow azonosítók létrehozása érdekében:
A fenti kódban egy táblázatot készítünk duplikált sorokkal. Egyedi azonosítókat generálunk a ROW_NUMBER () függvény segítségével, és a közös tábla kifejezés (CTE) használatával töröljük az ismétlődéseket:
Ez a kód azonban kompaktabb és optimálisabbra cserélhető:
Ennek ellenére meg lehet határozni a rowin SQL Server fizikai címét is. Annak ellenére, hogy gyakorlatilag lehetetlen hivatalos dokumentációt találni erről a szolgáltatásról, az Oracle ROWIDpseudo oszlopának analógjaként használható. A neve %% physloc %% (az SQL Server 2008 óta), és ez egy virtuális bináris (8) oszlop, amely a sor fizikai helyét mutatja. Mivel a %% physloc %% időértéke minden sorban egyedi, használhatjuk sorazonosítóként, amelyek egyedi index nélküli táblázatból ismétlődő sorokat távolítanak el. Így eltávolíthatunk többszörös sorokat egy táblából, az SQL Server egyedi indexe nélkül, mint az Oracleas-ban, vagy abban az esetben, ha a táblának egyedi indexe van.
Az alábbi első két lekérdezés az Oracle duplikátumok eltávolításának megfelelő változata, a következő kettő a duplikátumok eltávolításának lekérdezése a %% physloc %% similarto használatával, az egyedi indexű tábla esetével, az utolsó pedig lekérdezés, a %% physloc %% nem csak az összes opció teljesítményének összehasonlítására szolgál:
A végrehajtási terveket elemezve láthatjuk, hogy az első és az utolsó lekérdezés a leggyorsabb a teljes köteghez képest idők:
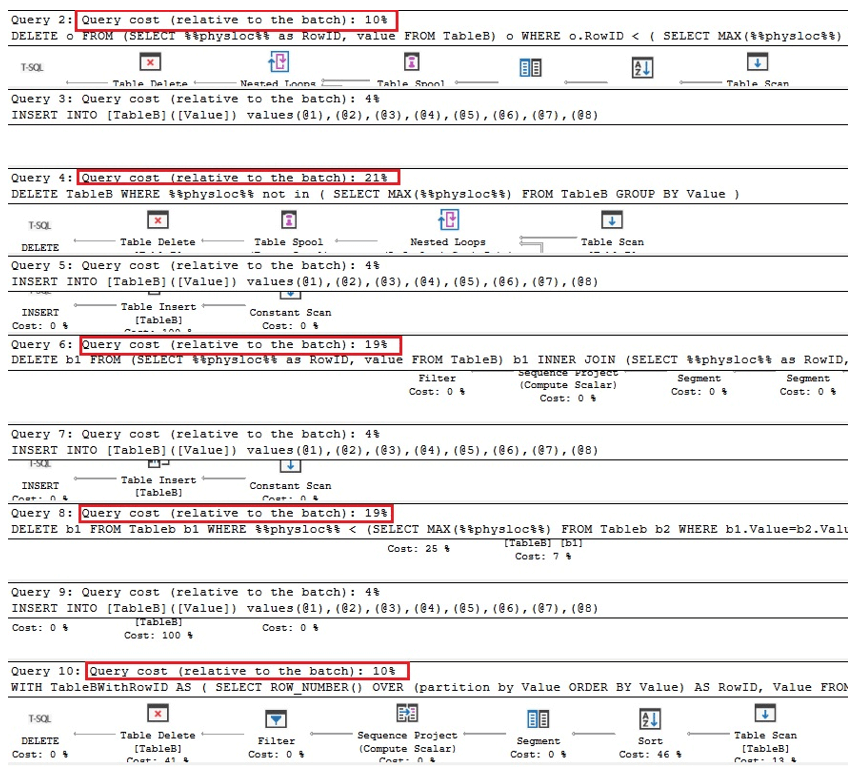
Ezért megállapíthatjuk, hogy általában a %% physloc %% használata nem javítja a teljesítményt. E megközelítés használata során nagyon fontos felismerni, hogy ez az SQL Server dokumentálatlan tulajdonsága, ezért a fejlesztőknek nagyon körültekintőnek kell lenniük. Például elkülönített sorokat tárolhatunk egy ideiglenes táblában, majd töröljük az összes adatot a táblánkból, és ezt követően külön sorokat helyezhetünk el az ideiglenes táblából az állandó táblánkba. Ebben az esetben a DELETE és INSERT utasításokat egy tranzakcióba kell foglalni.
Következtetés
Tapasztalataink során olyan helyzetekkel kell szembenéznünk, amikor meg kell tisztítanunk az SQL Server táblákból származó ismétlődő értékeket. Az ismétlődő értékek lehetnek az oszlopban, amely a követelményeink alapján duplikálódik, vagy a táblázat tartalmazhat ismétlődő sorokat. Mindkét esetben ki kell zárnunk az adatokat, hogy elkerüljük az adatbázisban történő duplikációt. Ebben a tippben néhány technikát ismertettünk, amelyek remélhetőleg hasznosak lehetnek az ilyen típusú problémák megoldásához.
Következő lépések
Utolsó frissítés: 2019-08-16


A szerzőről
 Sergey Gigoyan egy adatbázis-szakember, több mint 10 éves tapasztalattal, az adatbázis-tervezéssel, fejlesztéssel, teljesítményhangolással, optimalizálással, magas rendelkezésre állással, BI- és DW-tervezéssel.
Sergey Gigoyan egy adatbázis-szakember, több mint 10 éves tapasztalattal, az adatbázis-tervezéssel, fejlesztéssel, teljesítményhangolással, optimalizálással, magas rendelkezésre állással, BI- és DW-tervezéssel. Az összes megtekintése tippek
- További adatbázis-fejlesztői tippek …