Najít a odebrat duplicitní řádky z tabulky serveru SQL
Autor: Sergey Gigoyan | Aktualizováno: 2019-08-16 | Komentáře (11) | Související: Více > Návrh databáze
Problém
Podle doporučených postupů todatabasedesign by tabulka serveru SQL Server neměla obsahovat duplicitní řádky. Během procesu návrhu databáze by měly být vytvořeny primární klíče, aby se odstranily duplicitní řádky. Někdy však musíme pracovat s databázemi, kde tato pravidla nejsou dodržována nebo jsou možné výjimky (když jsou tato pravidla vědomě obcházena). Například když se používá pracovní tabulka a data se načítají z různých zdrojů, kde jsou možné duplicitní řádky. Po dokončení procesu načítání by měla být tabulka vyčištěna nebo by měla být načtena čistá data do trvalé tabulky, takže poté již duplikáty nebudou potřeba. Proto vyvstává problém týkající se odstranění duplikátů z tabulky načítání. V tomto tipu prozkoumáme některé způsoby, jak vyřešit potřebu odstranění duplikace dat.
Řešení
V tomto tipu budeme uvažovat o dvou případech:
- První případ je, když tabulka serveru SQL má primární klíč (nebo jedinečný index) a jeden ze sloupců obsahuje duplicitní hodnoty, které by měly být odstraněny.
- Druhým případem je, že tabulka nemá primární klíč nebo jakýkoli jedinečný index a obsahuje duplicitní řádky, které by měly být odstraněny. Pojďme o těchto případech samostatně.
Jak odstranit duplicitní řádky v tabulce serveru SQL Server
Duplikovat záznamy v tabulka serveru SQL může být velmi vážným problémem. Díky duplicitním údajům je možné objednávky zpracovat několikrát, mít nepřesné výsledky pro hlášení a další. Na serveru SQL Server existuje řada způsobů, jak adresovat duplicitní záznamy v tabulce na základě konkrétních okolností, například:
- Tabulka s jedinečným indexem – U tabulek s jedinečným indexem máte příležitost použít index na objednávku identifikuje duplicitní data a poté duplicitní záznamy odstraní. Identifikaci lze provést pomocí self-join, seřazením dat podle maximální hodnoty, pomocí funkce RANK nebo pomocí logiky NOT IN.
- Tabulka bez jedinečného indexu – u tabulek bez jedinečného indexu je to o něco více náročný. V tomto scénáři lze použít funkci ROW_NUMBER () s běžným tabulkovým výrazem (CTE) k seřazení dat a následnému odstranění následných duplicitních záznamů.
Podívejte se na níže uvedené příklady, abyste získali příklady z reálného světa o tom, jak odstranit duplicitní záznamy z tabulky.
Odebrání duplikátů řádků z tabulky serveru SQL Server s jedinečným indexem
Nastavení testovacího prostředí
Abychom splnili naše úkoly, potřebujeme testovací prostředí:
USE masterGOCREATE DATABASE TestDBGOUSE TestDBGOCREATE TABLE TableA( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Nyní nechme data vložit do „TableA“:
Jak vidíme, hodnoty 3 a 5 existují ve sloupci „Hodnota“ vícekrát:
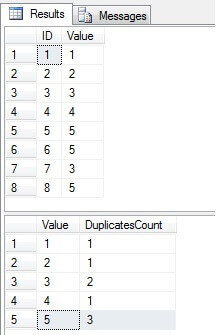
Identifikovat duplicitní řádky v tabulka serveru SQL
Naším úkolem je vynutit jedinečnost sloupce „Hodnota“ odstraněním duplikátů. Odstranění duplicitních hodnot z tabulky pomocí jedinečného indexu je o něco jednodušší než odebrání řádků z tabulky bez něj. ze všeho musíme najít duplikáty. Existuje mnoho různých způsobů, jak toho dosáhnout. Pojďme prozkoumejte a porovnejte některé běžné způsoby. V níže uvedeném kódu existuje šest řešení, jak najít duplicitní hodnoty, které by měly být odstraněny (ponechat pouze jednu hodnotu):
Jak vidíme, výsledek pro všechny případy je stejný:
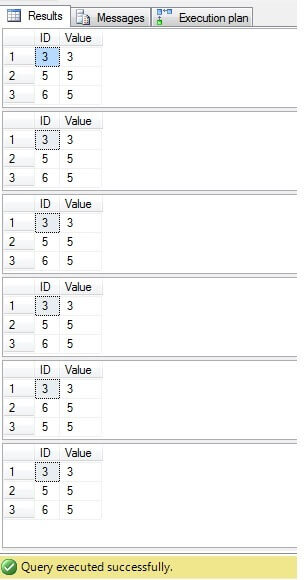
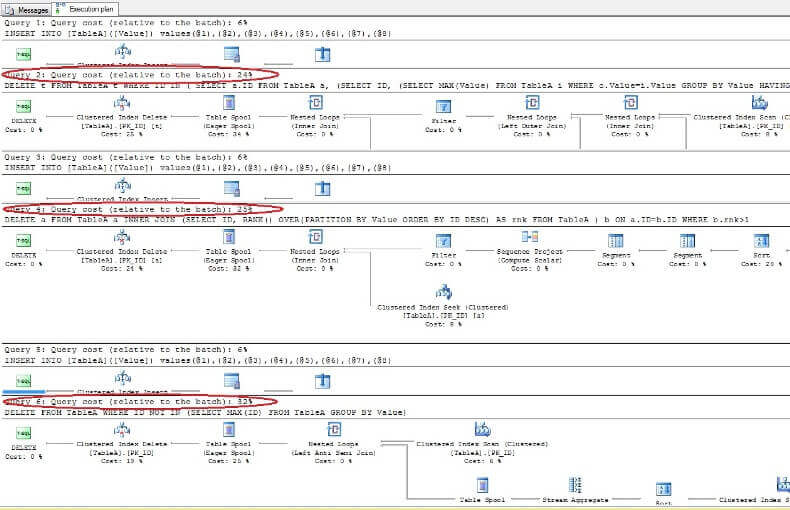
Je třeba smazat pouze řádky s ID = 3, 5, 6. Při pohledu na plán provádění vidíme, že nejnovější – nejkompaktnější řešení („Řešení 6“) má nejvyšší náklady (v našem příkladu je primární klíč ve sloupci „ID“, takže hodnoty „NULL“ nejsou pro tento sloupec, proto „NOT IN“ bude fungovat bez problémů) a druhý má nejnižší náklady:

mazání Duplikovat řádky v tabulce serveru SQL
Nyní pomocí těchto dotazů pojďme odstranit duplicitní hodnoty z tabulky. Zjednodušte náš proces, použijeme pouze druhý, pátý a šestý dotaz:
Smazání dat a opětovné prohlížení plánů provádění vidíme, že nejrychlejší je první příkaz DELETE a nejpomalejší je poslední podle očekávání:
Odebrání duplikátů z tabulky bez jedinečného indexu v ORACLE
Jako prostředek pro ilustraci našeho posledního příkladu v tomto tipu chci vysvětlit některé podobné funkce v Oracle. Odebrání duplikátu řádky z t schopný bez jedinečného indexu je v Oracle o něco jednodušší než v SQL Serveru. V Oracle je pseudo sloupec ROWID, který vrací adresu řádku. Jedinečně identifikuje řádek v tabulce (obvykle také v databázi, ale v tomto případě existuje výjimka – pokud různé tabulky ukládají data ve stejném klastru, mohou mít stejný ROWID).Dotaz níže vytváří a vkládá data do tabulky v databázi Oracle:
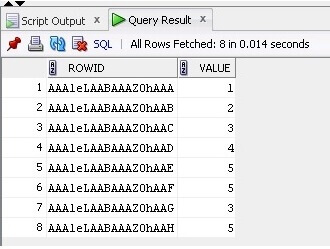
Nyní z tabulky vybíráme data a ROWID:
SELECT ROWID, Value FROM TableB;
Výsledek je uveden níže:
Nyní pomocí ROWID snadno odstraníme duplicitní řádky z tabulka:
DELETE TableBWHERE rowid not in ( SELECT MAX(rowid) FROM TableB GROUP BY Value );
Duplikáty také můžeme odstranit pomocí níže uvedeného kódu:
DELETE from TableB oWHERE rowid < ( SELECT MAX(rowid) FROM TableB i WHERE i.Value=o.Value GROUP BY Value );
Odebrání duplikátů z tabulky serveru SQL Server bez jedinečného indexu
Na rozdíl od Oracle není na serveru SQL Server žádný ROWID, takže pro odstranění duplikátů z tabulky bez jedinečný index, který potřebujeme k další generaci identifikátorů uniquerow:
Ve výše uvedeném kódu vytváříme tabulku s duplicitními řádky. Generujeme jedinečné identifikátory pomocí funkce ROW_NUMBER () a pomocí běžného tabulkového výrazu (CTE) odstraňujeme duplikáty:
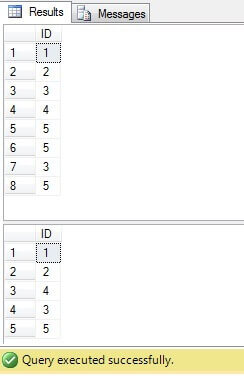
Tento kód však lze nahradit kompaktnějším a optimálnějším:
Z výše uvedeného je možné identifikovat také fyzickou adresu řádku na serveru SQL. Navzdory skutečnosti, že je prakticky nemožné najít oficiální dokumentaci k této funkci, lze ji použít jako analogický sloupec ROWIDpseudo v Oracle. Říká se tomu %% physloc %% (od SQL Server 2008) a jedná se o virtuální binární (8) sloupec, který zobrazuje fyzické umístění řádku. Protože hodnota %% physloc %% je pro každý řádek jedinečná, můžeme ji použít jako identifikátor řádku, který odstraní duplicitní řádky z tabulky bez jedinečného indexu. Můžeme tedy odstranit duplicitní řádky z tabulky bez jedinečného indexu na serveru SQL Server jako v Oracleasu, stejně jako v případě, že má tabulka jedinečný index.
První dva dotazy níže jsou ekvivalentní verze odstraňování duplikátů v Oracle, další dva jsou dotazy pro odstraňování duplikátů pomocí %% physloc %% obdobně jako v případě tabulky s jedinečným indexem a v posledním dotaz, %% physloc %% se nepoužívá jen k porovnání výkonu všech těchto možností:
Při analýze prováděcích plánů vidíme, že první a poslední dotaz jsou nejrychlejší ve srovnání s celkovou dávkou krát:
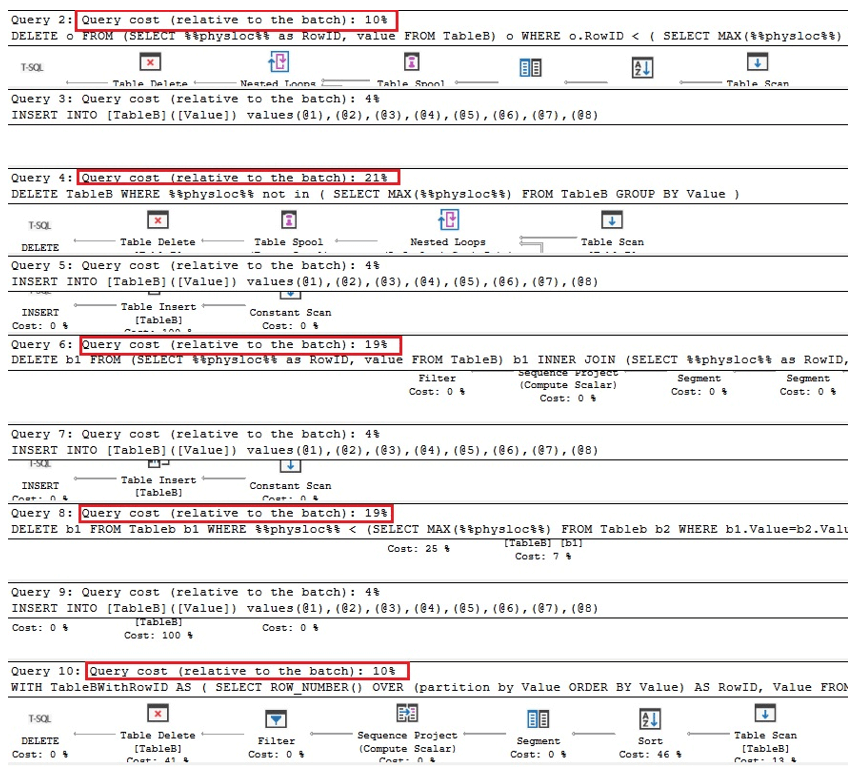
Proto můžeme dojít k závěru, že použití %% physloc %% obecně nezlepší výkon. Při používání tohoto přístupu je velmi důležité si uvědomit, že se jedná o nezdokumentovanou vlastnost serveru SQL Server, a proto by vývojáři měli být velmi opatrní.
Existují i jiné způsoby, jak odstranit duplikáty, o kterých tento tip nepojednává. Například můžeme do dočasné tabulky uložit odlišné řádky, poté odstranit všechna data z naší tabulky a poté vložit odlišné řádky z dočasné tabulky do naší trvalé tabulky. V tomto případě by měly být příkazy DELETE a INSERT zahrnuty do jedné transakce.
Závěr
Během našich zkušeností čelíme situacím, kdy musíme vyčistit duplicitní hodnoty z tabulek serveru SQL Server. Duplicitní hodnoty mohou být ve sloupci, který bude duplikován na základě našich požadavků, nebo tabulka může obsahovat duplicitní řádky. V obou případech musíme data vyloučit, abychom zabránili duplikaci dat v databázi. V tomto tipu jsme vysvětlili některé techniky, které snad pomohou vyřešit tyto typy problémů.
Další kroky
Poslední aktualizace: 2019-08-16


O autorovi
 Sergey Gigoyan je databázový profesionál s více než 10 lety zkušeností se zaměřením na návrh databáze, vývoj, ladění výkonu, optimalizaci, vysokou dostupnost, BI a DW design.
Sergey Gigoyan je databázový profesionál s více než 10 lety zkušeností se zaměřením na návrh databáze, vývoj, ladění výkonu, optimalizaci, vysokou dostupnost, BI a DW design. Zobrazit všechny moje tipy
- Další tipy pro vývojáře databází …